[帮助文档] 通过HBase Java API访问宽表引擎
本文介绍通过HBase Java API访问Lindorm宽表引擎的具体操作和使用示例。
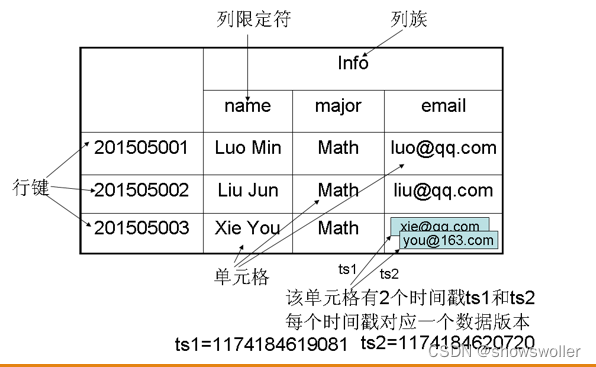
【大数据技术Hadoop+Spark】HBase数据模型、Shell操作、Java API示例程序讲解(附源码 超详细)
一、HBase数据模型HBase分布式数据库的数据存储在行列式的表格中,它是一个多维度的映射模型,其数据模型如下所示。表的索引是行键,列族,列限定符和时间戳,表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,列族支持动态扩展,可以很轻松的添加一个列族或者列,无须预先定义列的数量及数据...

[帮助文档] 如何通过HBaseJavaAPI访问Lindorm宽表引擎
Lindorm宽表引擎支持通过HBase Java API读写数据。本文介绍如何通过HBase Java API访问Lindorm宽表引擎。
[帮助文档] 如何通过HBase非JavaAPI连接并使用宽表引擎
云原生多模数据库 Lindorm宽表引擎支持通过HBase非Java(例如C++、Python和Go等)API进行访问,本文介绍具体的访问操作。
[帮助文档] HBaseJavaAPI访问宽表引擎的使用限制
Lindorm支持通过HBase Java API进行访问,但目前存在以下几个方面的使用限制。
[帮助文档] 如何使用SolrJavaAPI访问HBase增强版全文索引服务
云数据库HBase增强版全文索引服务支持多语言访问,并且完全兼容开源Apache Solr API,本文介绍如何使用Solr Java API访问云数据库HBase增强版全文索引服务。
spark大批量读取Hbase时出现java.lang.OutOfMemoryError: unable to create new native thread
这个问题我去网上搜索了一下,发现了很多的解决方案都是增加的nproc数量,即用户最大线程数的数量,但我修改了并没有解决问题,最终是通过修改hadoop集群的最大线程数解决问题的。并且网络上的回答多数关于增加nproc的答案不完整,我这里顺便记录一下。 用户最大线程数可以通过linux下的命令 uli...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









