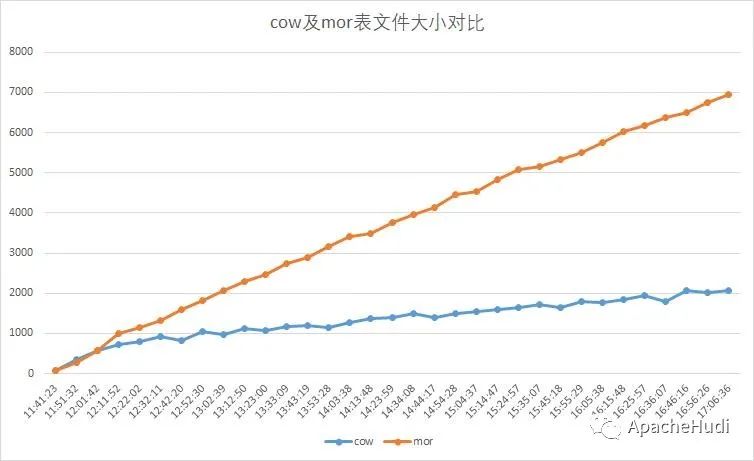
实战|使用Spark Streaming写入Hudi
1. 项目背景 传统数仓的组织架构是针对离线数据的OLAP(联机事务分析)需求设计的,常用的导入数据方式为采用sqoop或spark定时作业逐批将业务库数据导入数仓。随着数据分析对实时性要求的不断提高,按小时、甚至分钟级的数据同步越来越普遍。由此展开了基于spark/flink流处理机制的(准)实时...

手把手教你大数据离线综合实战 ETL+Hive+Mysql+Spark
引言大家好,我是ChinaManor,直译过来就是中国码农的意思,俺希望自己能成为国家复兴道路的铺路人,大数据领域的耕耘者,一个平凡而不平庸的人。1.第一章 综合实战概述数据管理平台(Data ManagementPlatform,简称DMP),能够为广告投放提供人群标签进行受众精准定向,并通过投放...


大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
一、概述Hudi(Hadoop Upserts Deletes and Incrementals),简称Hudi,是一个流式数据湖平台,支持对海量数据快速更新,内置表格式,支持事务的存储层、 一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具,它可以以极低的延迟将数据快...
![[实战系列]SelectDB Cloud Spark Connector 最佳实践](https://ucc.alicdn.com/pic/developer-ecology/rijsv7fdpwroq_028e77f8c3954b5bb7285508e6be6474.png)
[实战系列]SelectDB Cloud Spark Connector 最佳实践
前言企业正在经历其数据资产的爆炸式增长,这些数据包括批式或流式传输的结构化、半结构化以及非结构化数据,随着海量数据批量导入的场景的增多,企业对于 Data Pipeline 的需求也愈加复杂。新一代云原生实时数仓 SelectDB Cloud 作为一款运行于多云之上的云原生实时数据仓库,致力于通过开...
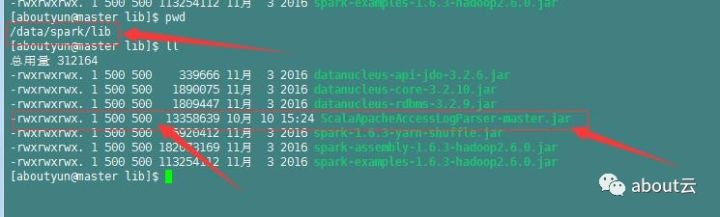
日志分析实战之清洗日志小实例3:如何在spark shell中导入自定义包
加载包上一篇文章,生成了包,那么这个包该如何加载到spark环境中,并且为我们所使用。那么首先改如何加载这个包。首先将这个包放到spark中的lib文件夹下。在复制到Linux中,首先需要修改的就是权限。我们看到用户和组的权限为500,并且用户,所属组,及其它用户都为满权限,可以通过下...
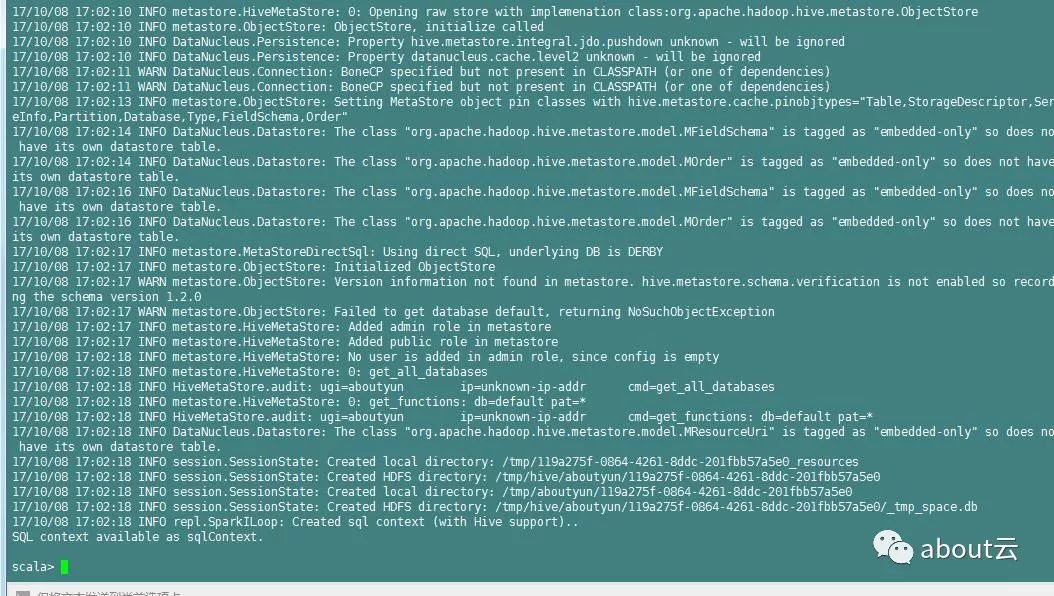
日志分析实战之清洗日志小实例1:使用spark&Scala分析Apache日志
about云日志分析,那么过滤清洗日志。该如何实现。这里参考国外的一篇文章,总结分享给大家。使用spark分析网站访问日志,日志文件包含数十亿行。现在开始研究spark使用,他是如何工作的。几年前使用hadoop,后来发现spark也是容易的。下面是需要注意的:如果你已经知道如何使用spark并想知...

大数据入门与实战-Spark上手
1 Spark简介1.1 引言行业正在广泛使用Hadoop来分析他们的数据集。原因是Hadoop框架基于简单的编程模型(MapReduce),它使计算解决方案具有可扩展性,灵活性,容错性和成本效益。在这里,主要关注的是在查询之间的等待时间和运行程序的等待时间方面保持处理大型数据集的速度。Spark由...
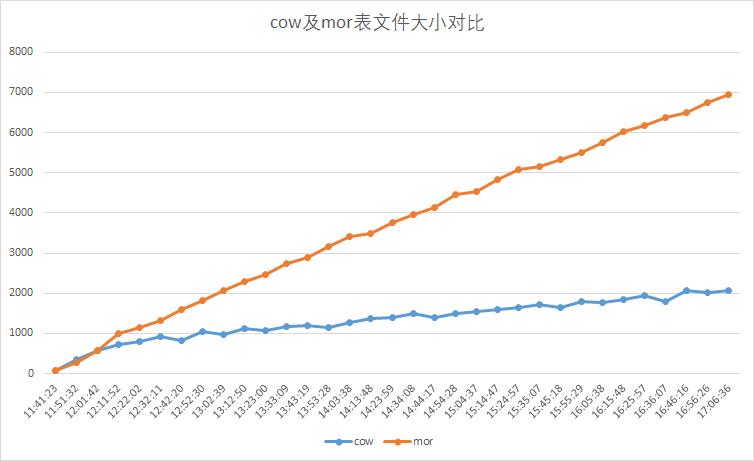
实战|使用Spark Structured Streaming写入Hudi
1. 项目背景传统数仓的组织架构是针对离线数据的OLAP(联机事务分析)需求设计的,常用的导入数据方式为采用sqoop或spark定时作业逐批将业务库数据导入数仓。随着数据分析对实时性要求的不断提高,按小时、甚至分钟级的数据同步越来越普遍。由此展开了基于spark/flink流处理机制的(准)实时同...

大数据上手实战!Spark 实战训练营第三季开启
8月18日,阿里巴巴大数据训练营“九营齐开”正式开营,来自数据计算、数据分析、数据仓库、搜索、机器学习、数据智能等多个领域的技术大佬亲身上阵教学,解读各技术领域基础原理,剖析行业实践案例,帮助开发者实现大数据从0到1的上手学习。 首期大数据“9营齐开”计划吸引了10000+开发者报名参与,成为今夏最...

实战 | 利用Delta Lake使Spark SQL支持跨表CRUD操作
本文转载自公众号: eBay技术荟作者 | 金澜涛原文链接:https://mp.weixin.qq.com/s/L64xhtKztwWhlBQrreiDfQ 摘要 大数据处理技术朝传统数据库领域靠拢已经成为行业趋势,目前开源的大数据处理引擎,如Apache Spark、Apache Hadoop、...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子







apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作