Python爬虫实战:利用代理IP爬取某瓣电影排行榜并写入Excel(附上完整源码)
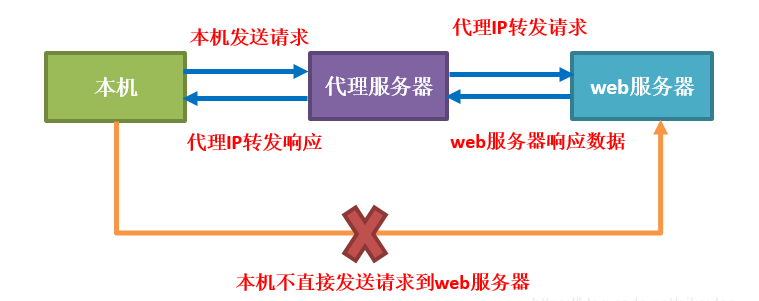
1. 爬虫和代理IP的关系 爬虫是指通过编写程序自动获取互联网上的信息的技术。爬虫可以模拟人的行为,在网页上浏览、点击、输入数据等,从而获取网页上的各种信息,如文本、图片、视频等。爬虫可以用于各种目的,如搜索引擎的索引、数据分析、信息监测等。 代理IP是指通过中间服务器转发网络请求的技术。在爬虫中,...
您好!请问一下,在从页面爬取数据写入excel的时候,能否让excel显示在最前面,让我能够看到数据
您好!请问一下,在从页面爬取数据写入excel的时候,能否让excel显示在最前面,让我能够看到数据爬取并存储的过程
Crawler:基于BeautifulSoup库+requests库+伪装浏览器的方式实现爬取14年所有的福彩网页的福彩3D相关信息,并将其保存到Excel表格中
输出结果本来想做个科学预测,无奈,我看不懂爬到的数据……得到数据:3D(爬取的14年所有的福彩信息).rar好吧,等我看到了再用机器学习算法预测一下……完整代码,请点击获取http://1111111111111核心代码import requestsimport BeautifulSoupimpor...
PythonSpider---爬取淘宝店铺信息并导入excel
挺久没更新简书了,之前一直在忙机器视觉的开题报告,现在又要期末复习,射频通信,信号处理看的脑阔疼,所以决定写个简单点的爬虫,放松下,换个环境,也顺便巩固下爬虫。 图片来自网络 0.运行环境 Python3.6.5 Pycharm win10 1.爬虫思维框架 框架 1:从上图中可以看出本次爬虫所用到...
爬取搜索出来的电影的下载地址并保存到excel
一、背景 利用Requests模块获取页面,BeautifulSoup来获取需要的内容,最后利用xlsxwriter模块讲内容保存至excel,首先通过讲关键字收拾出来的页面获取到子页面的url,然后再次去抓取获取到子页面的信息保存到excel 二、代码 编写了两个模块,geturldytt和get...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。





