[帮助文档] 迁移到新服务器上的网站, 使用PHP访问时提示“系统不支持”等信息, 如何处理??
本文介绍迁移到新服务器上的PHP网站,使用浏览器访问时提示“不支持MySQL”等信息的问题描述、问题原因和解决方案。
Crawler:基于requests库+urllib3库+伪装浏览器实现爬取抖音账号的信息数据
输出结果更新……代码设计from contextlib import closingimport requests, json, time, re, os, sys, timeimport urllib3urllib3.disable_warnings(urllib3.exceptions.Inse...
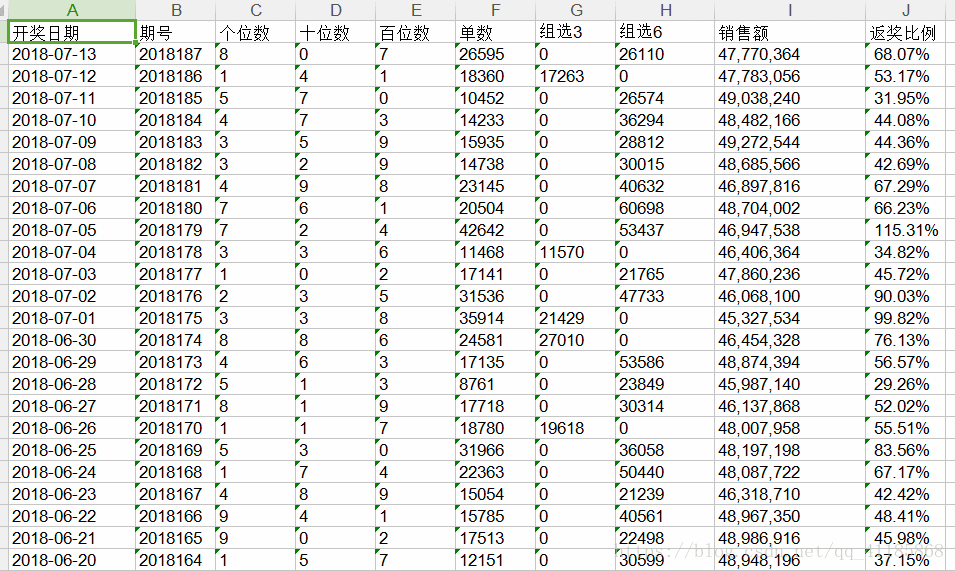
Crawler:基于BeautifulSoup库+requests库+伪装浏览器的方式实现爬取14年所有的福彩网页的福彩3D相关信息,并将其保存到Excel表格中
输出结果本来想做个科学预测,无奈,我看不懂爬到的数据……得到数据:3D(爬取的14年所有的福彩信息).rar好吧,等我看到了再用机器学习算法预测一下……完整代码,请点击获取http://1111111111111核心代码import requestsimport BeautifulSoupimpor...
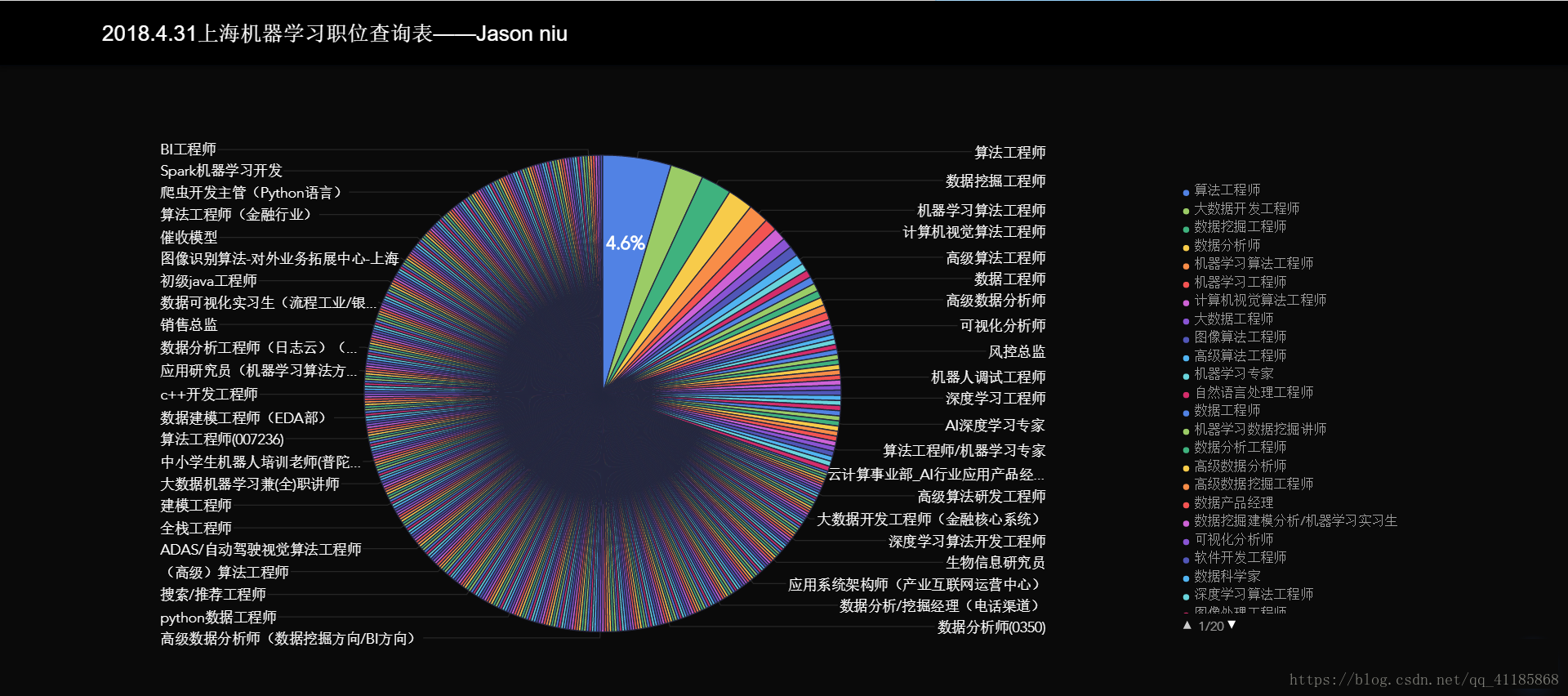
Crawler:基于urllib+requests库+伪装浏览器实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息(2018.4.30之前)并保存在csv文件内
输出结果设计思路核心代码# -*- coding: utf-8 -*-#Py之Crawler:爬虫实现爬取国内知名招聘网站,上海地区与机器学习有关的招聘信息并保存在csv文件内import reimport csvimport requestsfrom tqdm import tqdmfrom ur...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



