TensorRT部署系列 | 如何将模型从 PyTorch 转换为 TensorRT 并加速推理?
机器学习工程师的生活包括长时间的挫折和片刻的欢乐! 首先,努力让你的模型在你的训练数据上产生好的结果。您可视化您的训练数据,清理它,然后再次训练。您阅读了机器学习中的偏差方差权衡(bias variance tradeoff)以系统地处理训练过程。 有一天,你的 PyTorch 模型经过完美训练,可...

基于mps的pytorch 多实例并行推理
背景大模型训练好后,进行部署时,发现可使用的显卡容量远大于模型占用空间 。是否可以同时加载多个模型实例到显存空间,且能实现多个实例同时并发执行?本次实验测试基于mps的方案,当请求依次过来时,多个相同的实例推理任务就可以同时运行。显然,该方法需要显卡测提供某种支持。这种就是 nvidia 的 Mul...
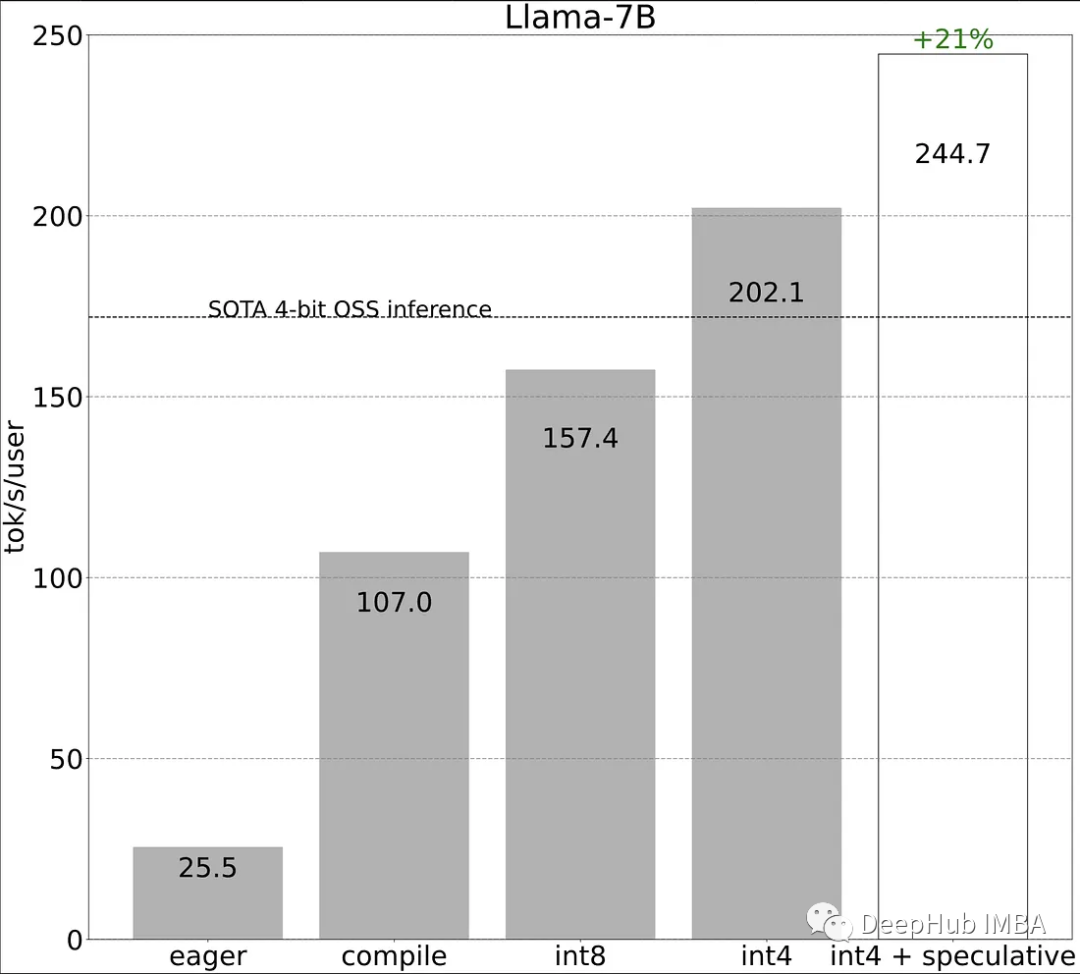
使用PyTorch II的新特性加快LLM推理速度
Torch.compile: PyTorch模型的编译器 GPU量化:通过降低精度操作来加速模型 推测解码:使用一个小的“草稿”模型来加速llm来预测一个大的“目标”模型的输出 张量并行:通过在多个设备上运行模型来加速模型。 我们来看看这些方法的性能比较: 作为对比,传统的方式进行LLaMA-7b的...
ModelScope我可以用pytorch去加载模型推理吗?
ModelScope中我看模型merge后的模型都是pytorch的结果,我可以用pytorch去加载模型推理吗?
模型如何下载到本地,并通过本地pytorch或tensorflow runtime 运行推理?
模型如何下载到本地,并通过本地pytorch或tensorflow runtime 运行推理?

pytorch模型转ONNX、并进行比较推理
pytorch模型转ONNX概述ONNX(Open Neural Network Exchange)是一种开放式的深度学习模型交换格式,旨在促进不同深度学习框架之间的互操作性。通过将深度学习模型转换为ONNX格式,可以将其从一个深度学习框架移植到另一个框架中,而无需重新训练模型或手动重新实现模型结构...

PyTorch宣布支持苹果M1芯片GPU加速:训练快6倍,推理提升21倍
今年 3 月,苹果发布了其自研 M1 芯片的最终型号 M1 Ultra,它由 1140 亿个晶体管组成,是有史以来个人计算机中最大的数字。苹果宣称只需 1/3 的功耗,M1 Ultra 就可以实现比桌面级 GPU RTX 3090 更高的性能。随着用户数量的增长,人们已经逐渐接受使用 M1 芯片的计...
在pytorch中,模型权重的精度会影响模型在cpu上的推理速度吗?
问题:在用pytorch训练模型时发现,模型训练的eopch越多,保存模型时模型权重的精度越好,模型在cpu上的推理的速度越慢,是因为模型权重精度会影响推理速度吗?如何调整pytorch模型参数的精度?不会,模型精度取决于模型对数据集的拟合是否到位,模型精度只是随着模型权重参数的迭代更新改变,但模型...
PyTorch 2.0 推理速度测试:与 TensorRT 、ONNX Runtime 进行对比
这对我们来说是一个好消息,训练时间改进的结果令人印象深刻。PyTorch 团队在发布新闻稿和 PyTorch GitHub 上没有提到的是 PyTorch 2.0 推理性能。所以我们来对推理的速度做一个简单的研究,这样可以了解 PyTorch 2.0 如何与其他推理加速器(如 Nvidia Tens...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。