还有这种骚操作:使用Golang实现无头浏览器浏览和截图
前言在Web开发中,有时需要对网页进行截图,以便进行页面预览、测试等操作。而使用无头浏览器来实现截图功能,可以避免手动操作的繁琐和不稳定性。这篇文章将介绍:使用Golang进行无头浏览器的截图,轻松实现页面预览、测试和模拟用户操作。有趣这篇文章发完,有朋友在朋友圈留言说:没想到还有这种骚操作~还有朋...
我FC搭建的flask服务,浏览器打开默认是下载,怎么设置成是 浏览器浏览?
我FC搭建的flask服务,浏览器打开默认是下载,怎么设置成是 浏览器浏览?
在上传文件后,返回的文件url在浏览器打开默认会下载;如何变为直接在浏览器浏览?
看了这个文档管理文件元信息,不是很明白如何操作。 尝试了在上传时设置headers为 headers: { 'Content-Disposition': 'inline', 'x-oss-meta-Content-Disposition': 'inline', 'x-oss-meta-content...
我们设计的RPA流程跑一段时间后,图形验证码识别通过率断崖式下降,需要清理浏览器浏览数据后才能恢复正
我们设计的RPA流程跑一段时间后,图形验证码识别通过率断崖式下降,需要清理浏览器浏览数据后才能恢复正常 请问在RPA中如何清理浏览数据?
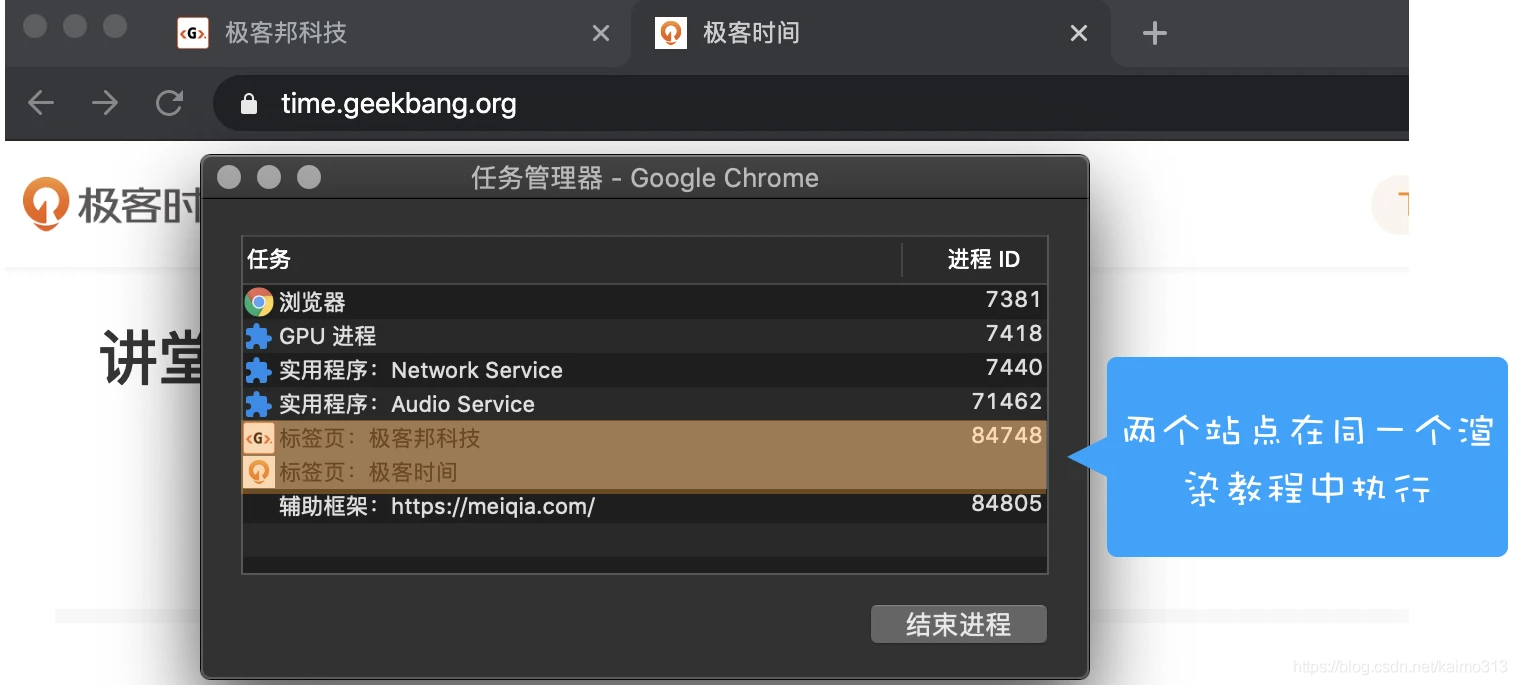
浏览器原理 36 # 浏览上下文组:如何计算Chrome中渲染进程的个数?
说明浏览器工作原理与实践专栏学习笔记前言在默认情况下,如果打开一个标签页,那么浏览器会默认为其创建一个渲染进程。如果从一个标签页中打开了另一个新标签页,当新标签页和当前标签页属于同一站点(相同协议、相同根域名)的话,那么新标签页会复用当前标签页的渲染进程。多个标签页运行在同一个渲染进程:从标签页中打...
使用python获取浏览器收藏夹和历史浏览记录,然后可以...
在电脑上浏览个网页,都要用到浏览器,当你打开网页的那一刻,浏览器就会记录你的浏览信息,这些信息可能就是你的信息泄露的根源。下面看看如何使用python获取一下历史浏览记录;以chrome浏览器为例:找到浏览器数据存放位置数据存放位置一般都是固定的,基本都在以下位置C:\Users\Administr...
QT调用IE浏览器COM插件完成网页浏览
一、可用的嵌入式浏览器方案QT在5.6之前可以webkit浏览器框架访问网页,在之后就去掉了webkit,加入了QWebEngineView框架,但是QWebEngineView只能支持VS编译器,mingw编译器不支持。在后面的高版本QT里,mingw编译器如果要加载网页可以使用两种方式。(1)....
Chrome 浏览器降级后浏览网站不保留用户数据问题原因及解决方法
由于浏览器降级导致新浏览器的数据不被老浏览器兼容。 我的 jira 系统登录很多次了,每次重启浏览器一点记录都没有了,勾选记住登录信息也不管用。解决方案如下: 1. 升级 chrome,兼容了就 ok 了。 2. 删部分用户数据(一般问题可解决)。 3. 删整个 Default 用户数据,重新生成&...
在Internet上浏览时,浏览器和WWW服务器之间传输网页使用的协议是什么呢?
在Internet上浏览时,浏览器和WWW服务器之间传输网页使用的协议是什么呢?
最新的移动端uc浏览器 不能跳转支付宝报关接口,别的浏览能够顺利跳转
window.location.href = https://mapi.alipay.com/gateway.do?${code}
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。



