大规模集群下Hadoop NameNode如何承载每秒上千次的高并发访问
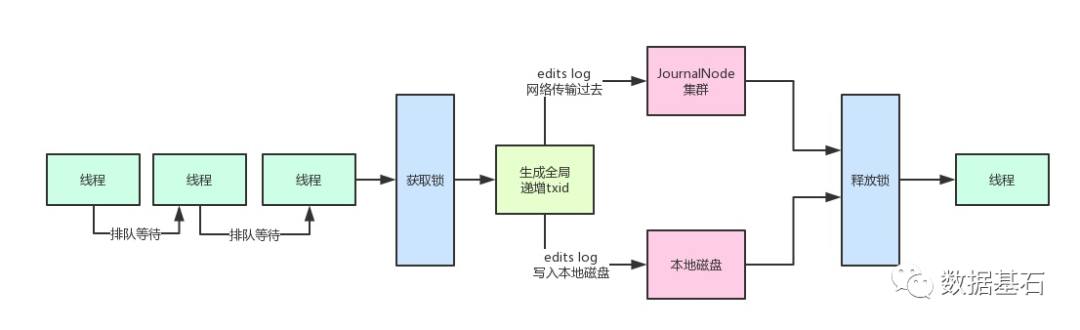
一、问题起源高并发请求 NameNode 会遇到什么样的问题?现在大家都明白每次请求 NameNode 修改一条元数据(比如说申请上传一个文件,那么就需要在内存目录树中加入一个文件),都要写一条 edits log,包括两个步骤:写入本地磁盘。通过网络传输给 JournalNodes 集群。但是如果...
Hadoop高并发?
Hadoop高并发?

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








