
基于node.js开发的文章生成器(三、占位符的替换与段落的生成与文章的生成)
引言前面我们已经学会了随机抽取语料库,接下来我们来真正意义上的合成句子。生成废话的样子大概是这样但是前面我们提取到的data是带有一定占位符的,首先我们就要完成占位符的替换。占位符的替换接下来我们来做占位符的替换,我们定义一个sentence的函数,然后传入两个参数,pick和replacer,其中...
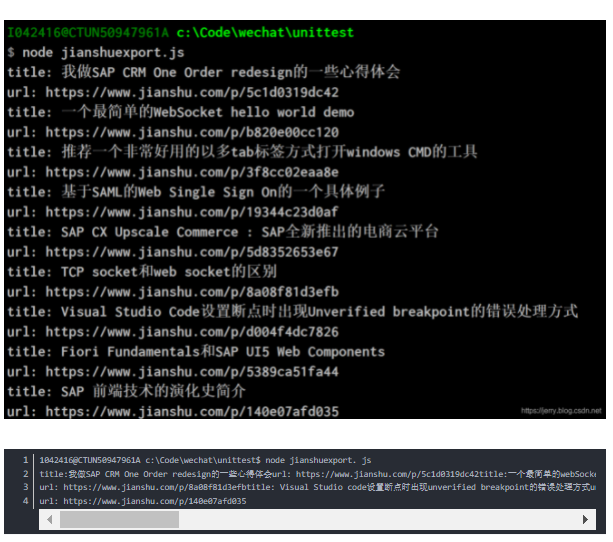
使用nodejs将某个简书用户的文章进行导出
var request = require('request'); var jsdom = require("jsdom"); var JSDOM = jsdom.JSDOM; const PREFIX = "https://www.jianshu.com"; /* a given article:...

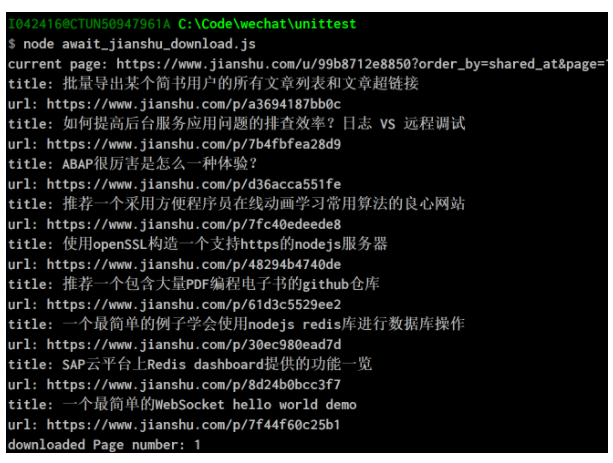
使用await和async关键字开发nodejs应用批量取出简书网站的文章标题和超链接
async function downloadArticle(pageNumber){ var url = PAGE + pageNumber; console.log("current page: " + url); var pageOptions = { url: url, method: "....
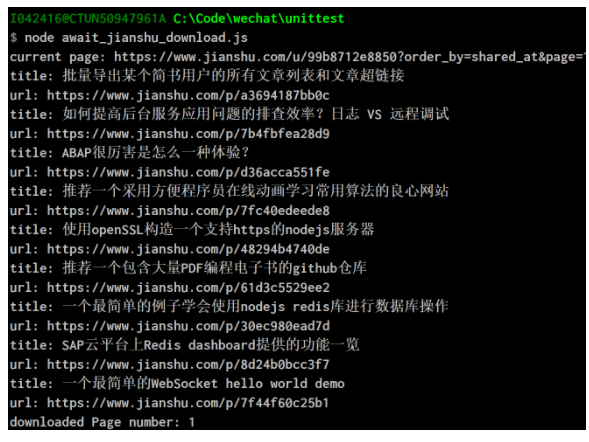
使用await和async关键字开发nodejs应用批量取出简书网站的文章标题和超链接
ES6的await和async出来已经那么久了,一起来学习一下吧。还是用我之前的读取某个简书用户所有文章列表的例子。先看主函数框架:async function downloadArticle(pageNumber){ var url = PAGE + pageNumber; console.log...

从零开始nodejs系列文章
从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发。Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎。chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的web开发框架Express,可...
Node.js 读取博客首页并获得文章标题
app.js // 内置http模块,提供了http服务器和客户端功能 var http=require("http"); // 内置文件处理模块 var fs=require('fs'); // 创建一个将流数据写入文件的WriteStream对象 var outstream=fs.createW...
NodeJS写个爬虫,把文章放到kindle中阅读
这两天看了好几篇不错的文章,有的时候想把好的文章 down 下来放到 kindle 上看,便写了个爬虫脚本,因为最近都在搞 node,所以就很自然的选择 node 来爬咯~ 本文地址:http://www.cnblogs.com/hustskyking/p/spider-with-node.html...
简易nodejs爬虫抓取博客园指定用户的文章及浏览量
需要安装nodejs和cheerio模块 实现了自定义用户,自定义页数,抓取完毕自动停止无重复 可以按需修改文章类和评论的类名 用法: 首先 npm install cheerio 执行 node cnblog [username] 文件结果保存在res/cnblog.tx...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。





