Flink CDC + Hudi + Hive + Presto构建实时数据湖最佳实践
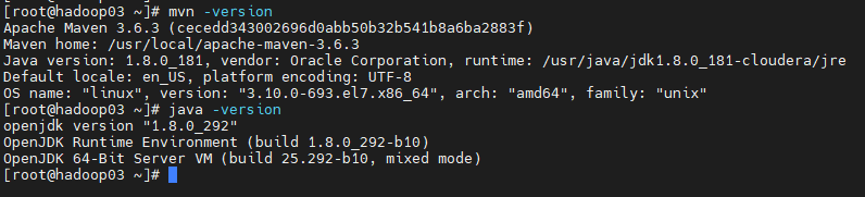
1. 测试过程环境版本说明 Flink1.13.1 Scala2.11 CDH6.2.0 Hadoop3.0.0 Hive2.1.1 Hudi0.10(master) PrestoDB0.256 Mysql5.7 2. 集群服务器基础环境 2.1 Maven和JDK环境版本 ...
[帮助文档] 如何使用DLASpark访问用户VPC中的Hive集群
本文主要介绍如何使用DLA Spark访问用户VPC中的Hive集群。

流数据湖平台Apache Paimon(四)集成 Hive 引擎
第3章 集成 Hive 引擎前面与Flink集成时,通过使用 paimon Hive Catalog,可以从 Flink 创建、删除、查询和插入到 paimon 表中。这些操作直接影响相应的Hive元存储。以这种方式创建的表也可以直接从 Hive 访问。更进一步的与 Hive 集成,可以使用 Hiv...
[帮助文档] 如何在新版控制台使用Dataflow集群连接DLF并读取Hive全量数据
EMR-3.38.3及后续版本的EMR集群可以使用数据湖元数据DLF(Data Lake Formation)服务对集群数据进行统一管理,EMR中的Flink组件在开源Flink基础上增加了与DLF适配的功能。本文为您介绍如何在EMR集群上通过Flink SQL创建Hive Catalog连接到DL...
[帮助文档] 通过DLA连接数据源Hive
本实例展示如何将Hive数据加载到DLA Ganos进行分析。
Hive 数仓迁移 JindoFS/OSS 数据湖最佳实践
Hive 数仓是大多数迁移客户都会遇到的场景。在迁移过程中,不建议同时在新集群进行业务升级(比如从 Hive on MR 迁移到 Hive on Tez 或 Spark SQL等),这些业务...

数据湖实操讲解【 JindoTable 计算加速】第二十二讲:对 Hive 数仓表进行高效小文件合并
本期导读 :【JindoTable 计算加速】第二十二讲主题:对 Hive 数仓表进行高效小文件合并d + JindoFS 对 OSS 上数据进行训练加速讲师:辰石,阿里巴巴计算平台事业部 技术专家内容框架:背景介绍主要功能实操演示直播回放链接:(22讲)https://dev...

数据湖实操讲解【 JindoTable 计算加速】第二十一讲:分层更高效,对 Hive 数仓进行热度/冷度统计
本期导读 :【JindoTable 计算加速】第二十一讲主题:分层更高效,对 Hive 数仓进行热度/冷度统计uid + JindoFS 对 OSS 上数据进行训练加速讲师:羊川,阿里巴巴计算平台事业部 开发工程师内容框架:热/冷度统计介绍热/冷度统计用法演示直播回放链接:(2...

数据湖实操讲解【数据迁移】第四讲:如何将 Hive 数据按分区归档到 OSS
本期导读 :【数据迁移】第四讲主题:如何将 Hive 数据按分区归档到 OSS讲师:健身,阿里巴巴计算平台事业部 EMR 技术专家内容框架:背景/具体功能介绍实现原理详解使用实例直播回放链接:(3/4讲)https://developer.aliyun.com/live/246750一、背景/功能简...
OSS数据湖实践——EMR + Hive + OSS案例
Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理;本文通过一个简单的示例来展现如何结合OSS+EMR+Hive来分析OSS上的数据。 前提条件 • 已注册阿里云账号,详情请参见注册云账号。• 已开通E-MapReduce服务和OSS服务。• 已完成云...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。