基于Python实现MapReduce
一、什么是MapReduce 首先,将这个单词分解为Map、Reduce。 Map阶段:在这个阶段,输入数据集被分割成小块,并由多个Map任务处理。每个Map任务将输入数据映射为一系列(key, value)对,并生成中间结果。 Reduce阶段:在这个阶段,中间结果被重新分组和排序,以便相同key...
[帮助文档] FlinkPython有哪些使用方法
本文通过以下方面,为您介绍Flink Python的使用方法。


数据分享|Python、Spark SQL、MapReduce决策树、回归对车祸发生率影响因素可视化分析
相关视频 项目挑战 ...
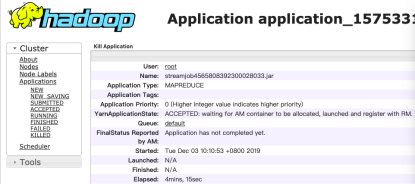
在本地python进行mapreduce时遇到的一些麻烦
之前在服务器正常运行的程序放到本地,确报了好几个错误执行cat input.txt | ./map.py报错 1 sh: ./map.py: Permission denied解决方法#赋予可执行权限 chmod -Rf 777 文件夹路径1解决之后报错 2 ./map.py: line 1: im...
centos7 伪分布式 hadoop 利用 python 执行 mapreduce
阅读本文之前 需要先在 服务器端配置好 伪分布的 hadoop可以参考博主之前的文章!!!!先记录一下自己遇到的坑hadoop 找不到python安装python 后还需要在 py文件中添加#! python执行路径#!/usr/local/python3/Python-3.6.5/python3否...
[帮助文档] 如何使用PythonClient编程方式访问TrinoOnACK服务
本文为您介绍如何使用Python Client编程的方式访问Trino On ACK服务并执行查询操作。
[帮助文档] PySpark中的Python环境介绍
EMR DataLake和自定义集群安装的Spark版本对Python环境的依赖各不相同。本文以Python3为例,介绍不同Spark版本所对应的Python版本,以及安装Python第三方库的方法。
Python实现一个最简单的MapReduce编程模型WordCount
MapReduce编程模型:Map:映射过程Reduce:合并过程import operator from functools import reduce # 需要处理的数据 lst = [ "Tom", "Jack", "Mimi", "Jiji",...
python中的MapReduce是什么?
python中的MapReduce是什么?
Python实现一个最简单的MapReduce编程模型WordCount
MapReduce编程模型:Map:映射过程Reduce:合并过程 import operator from functools import reduce # 需要处理的数据 lst = [ "Tom", "Jack", "Mimi", "Jiji"...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。