
大数据开发岗面试复习30天冲刺 - 日积月累,每日五题【Day30】——Spark数据调优(文末附完整文档)
停不要往下滑了,默默想5min,看看这些面试题你都会吗?一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个task,都是以每个task一条线程的方式,多线程并发运行的。一个应用提交的时候设置多大的内存?设置多少Core?设置几个Executor?以下答案仅供参考:...
回答粉丝疑问:Spark为什么调优需要降低过多小任务,降低单条记录的资源开销?
ChatGPT的答案:当Spark处理大量小任务时,会产生大量的网络通信,这会导致性能下降。此外,处理小任务时,单条记录的资源开销也会增加,这会使性能下降。因此,调优时需要尽量减少小任务的数量,以及降低单条记录的资源开销,以提高性能。降低过多小任务:filter操作使用不当,很容易引发麻烦。假如一个...

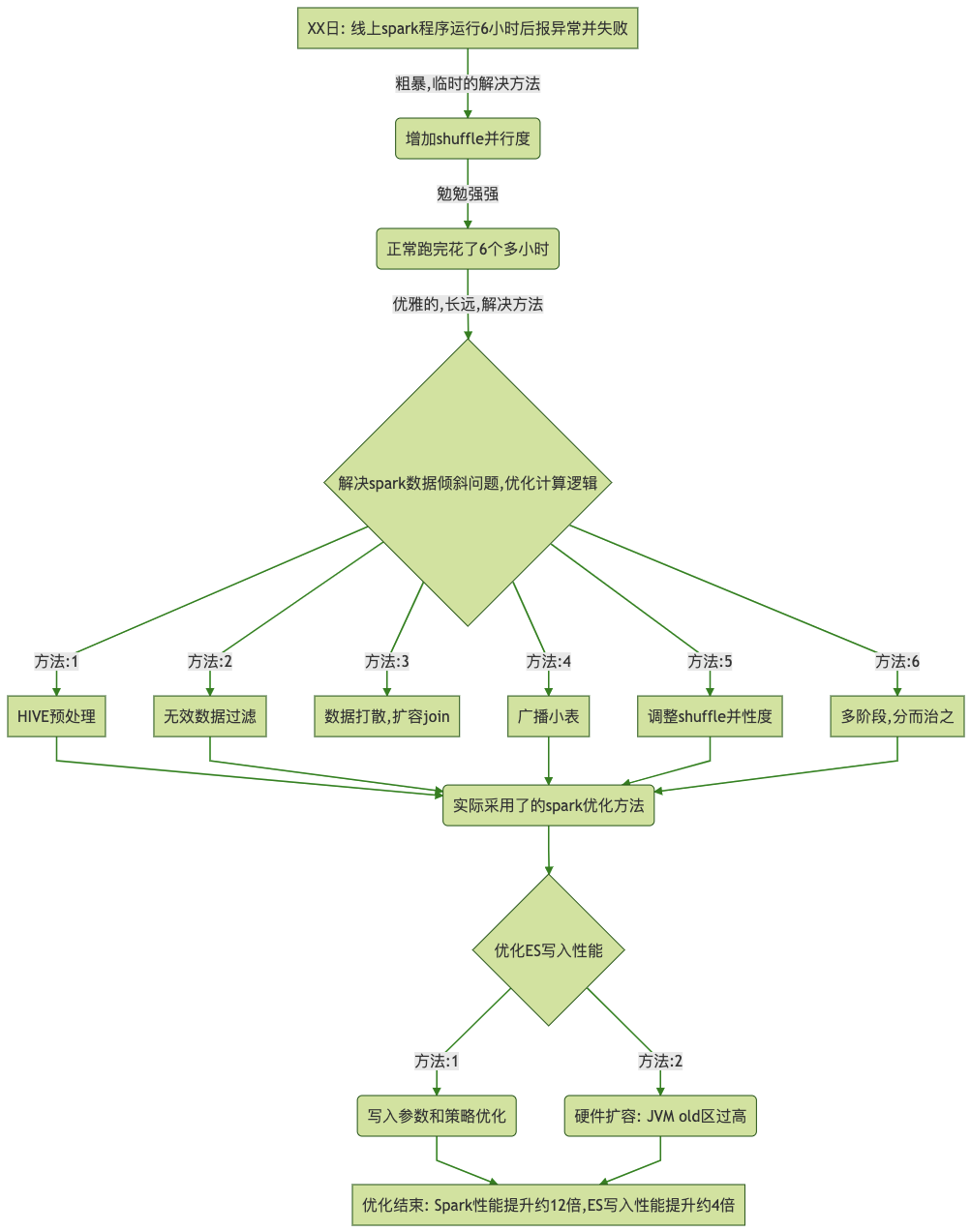
工作经验分享:Spark调优【优化后性能提升1200%】
优化后效果1.业务处理中存在复杂的多表关联和计算逻辑(原始数据达百亿数量级)2.优化后,spark计算性能提升了约12倍(6h-->30min)3.最终,业务的性能瓶颈存在于ES写入(计算结果,ES索引document数约为21亿 pri.store.size约 300gb)1. 背景业务数据...

工作常用之Spark调优【二】资源调优
第 2 章 资源调优2.1 资源规划2.1.1 资源设定考虑1 、总体原则以单台服务器 128G 内存, 32 线程为例。先设定单个 Executor 核数,根据 Yarn 配置得出每个节点最多的 Executor 数量,每个节点的 yarn 内存 / 每个节点数量 = 单个节点的数量总的 exec...
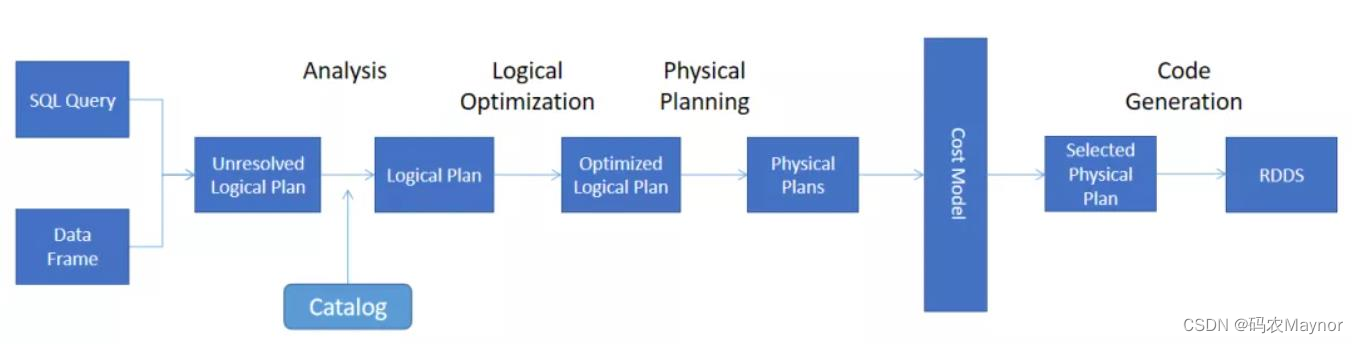
工作常用之Spark调优【一】
第 1 章 Explain 查看执行计划Spark 3.0 大版本发布, Spark SQL 的优化占比将近 50% 。 Spark SQL 取代 Spark Core ,成为新一代的引擎内核,所有其他子框架如 Mllib 、 Streaming 和 Graph ,都可以共享 SparkSQL 的性...
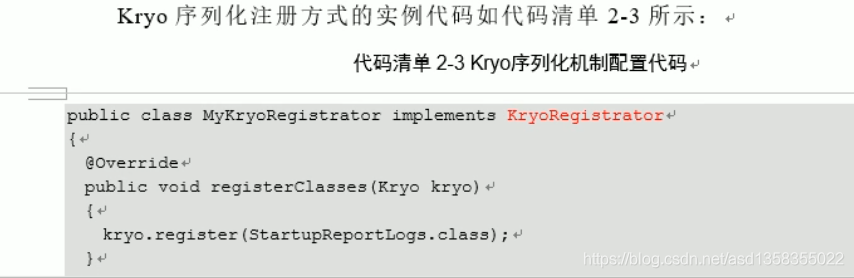
每日积累【Day2】SPARK调优
Spark常规优化 executor核心数量设置为Task的 1/3 或者 1/2,官方推荐Task数量为Spark设定的CPU cores的2 到 3倍 RDD优化:当多次对一个RDD进性多次计算时,都需要对这个RDD的父RDD重写进行计算时,可以为这个父RDD进性持久化,意思是对多次使用的RDD...

【Spark 调优】Spark 开发调优的十大原则
Spark的调优是面试或者笔试考察的重点:总结下1.开发调优: 原则一:避免创建重复的RDD。原则二:尽可能复用同一个RDD。原则三:对多次使用的RDD进行持久化。原则四:尽量避免使用shuffle类算子 。原则五:使用map-side预聚合的shuffle操作。原则六:使用高性能的算...
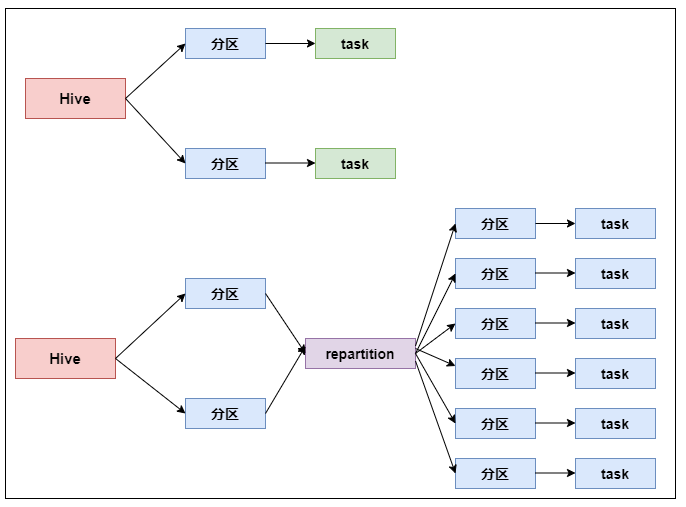
Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏) (二)
6. 并行度设置Spark作业中的并行度指各个stage的task的数量。如果并行度设置不合理而导致并行度过低,会导致资源的极大浪费,例如,20个Executor,每个Executor分配3个CPU core,而Spark作业有40个task,这样每个Executor分配到的task个数是2个,这就...
Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏) (一)
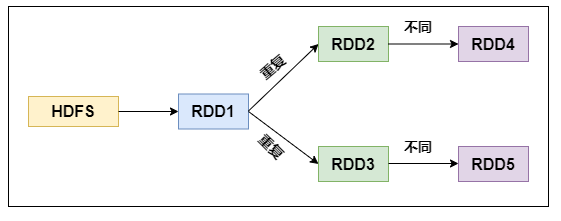
RDD算子调优不废话,直接进入正题!1. RDD复用在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示:对上图中的RDD计算架构进行修改,得到如下图所示的优化结果:2. 尽早filter获取到初始RDD后,应该考虑尽早地过滤掉不需要的数据...

Spark面试题(五)——数据倾斜调优
1、数据倾斜数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。数据倾斜俩大直接致命后果。1、数据倾斜直接会导致一种情况:Out Of Memory。2、运行速度慢。主要是发生在Sh...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多调优相关
apache spark您可能感兴趣
- apache spark应用
- apache spark SQL
- apache spark原理
- apache spark产品
- apache spark k8s
- apache spark深度学习
- apache spark集群
- apache spark分析
- apache spark数据
- apache spark数据库
- apache spark streaming
- apache spark Apache
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark任务
- apache spark程序