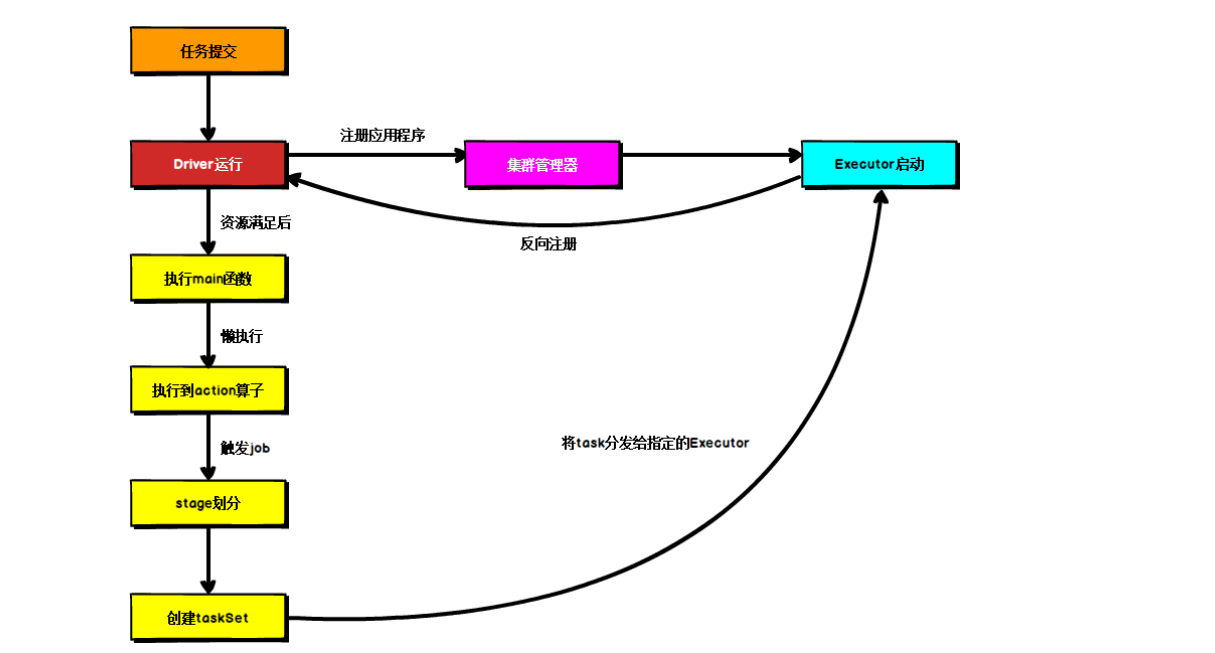
Spark学习---day06、Spark内核(源码提交流程、任务执行)
这是本人的学习过程,看到的同道中人祝福你们心若有所向往,何惧道阻且长; 但愿每一个人都像星星一样安详而从容的,不断沿着既定的目标走完自己的路程; 最后想说一句君子不隐其短,不知则问,不能则学。 如果大家觉得我写的还不错的话希望可以收获关注、点赞、收藏(谢谢大家) org.apache.spark.d...
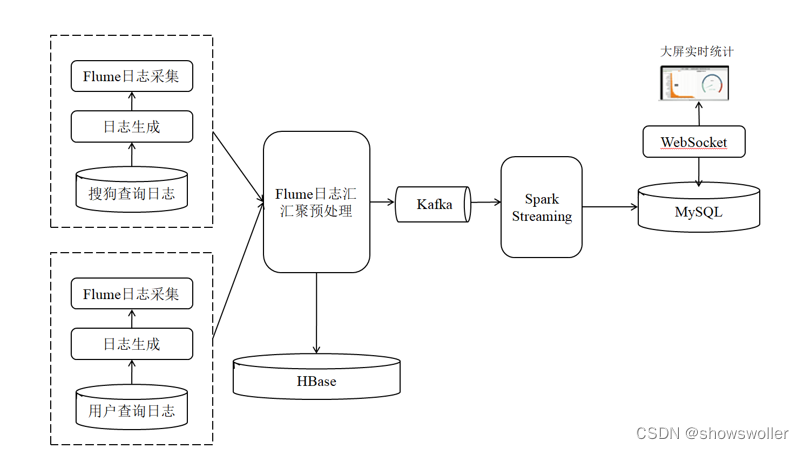
【Kafka+Flume+Mysql+Spark】实现新闻话题实时统计分析系统(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~系统简介新闻话题实时统计分析系统以搜狗实验室的用户查询日志为基础,模拟生成用户查询日志,通过Flume将日志进行实时采集、汇集,分析并进行存储。利用Spark Streaming实时统计分析前20名流量最高的新闻话题,并在前端页面实时显示结果。系统总体架构...

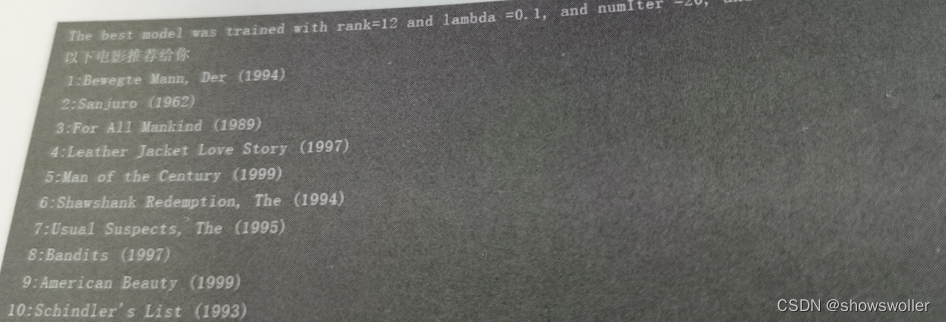
【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~协同过滤————电影推荐协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。在电影推荐系统中,通常分为针对用户推荐电...

【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~线性回归过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10通...
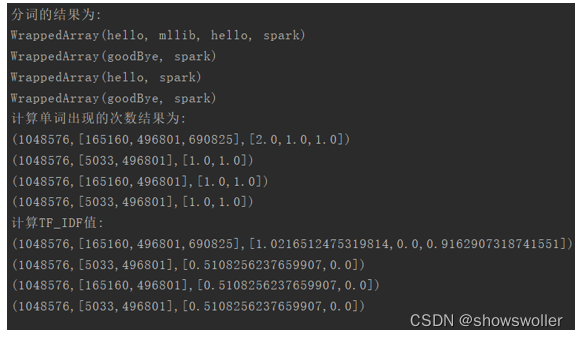
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...

【大数据技术】Spark+Flume+Kafka实现商品实时交易数据统计分析实战(附源码)
需要源码请点赞关注收藏后评论区留言私信~~~Flume、Kafka区别和侧重点1)Kafka 是一个非常通用的系统,你可以有许多生产者和消费者共享多个主题Topics。相比之下,Flume是一个专用工具被设计为旨在往HDFS,HBase等发送数据。它对HDFS有特殊的优化,并且集成了Hadoop的安...

【大数据技术Spark】DStream编程操作讲解实战(图文解释 附源码)
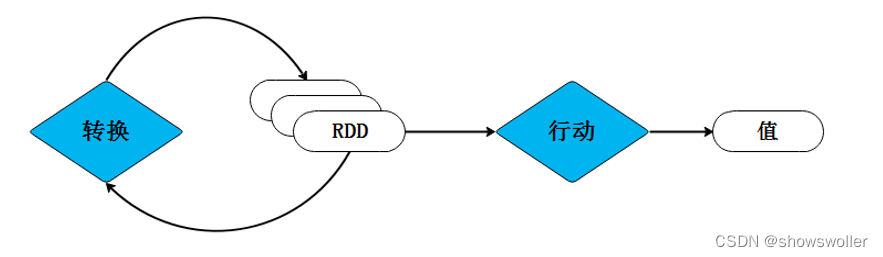
DStream编程批处理引擎Spark Core把输入的数据按照一定的时间片(如1s)分成一段一段的数据,每一段数据都会转换成RDD输入到Spark Core中,然后将DStream操作转换为RDD算子的相关操作,即转换操作、窗口操作以及输出操作。RDD算子操作产生的中间结果数据会保存在内存中,也可...
【大数据技术Spark】Spark SQL操作Dataframe、读写MySQL、Hive数据库实战(附源码)
需要源码和依赖请点赞关注收藏后评论区留言私信~~~一、Dataframe操作步骤如下1)利用IntelliJ IDEA新建一个maven工程,界面如下2)修改pom.XML添加相关依赖包3)在工程名处点右键,选择Open Module Settings4)配置Scala Sdk,界面如下5)新建文件...
【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建R...
【大数据技术Hadoop+Spark】HBase数据模型、Shell操作、Java API示例程序讲解(附源码 超详细)
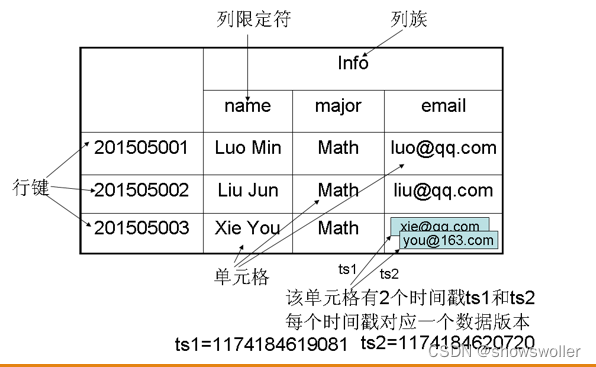
一、HBase数据模型HBase分布式数据库的数据存储在行列式的表格中,它是一个多维度的映射模型,其数据模型如下所示。表的索引是行键,列族,列限定符和时间戳,表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,列族支持动态扩展,可以很轻松的添加一个列族或者列,无须预先定义列的数量及数据...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多源码相关
apache spark您可能感兴趣
- apache spark大数据计算
- apache spark client
- apache spark报错
- apache spark模式
- apache spark任务
- apache spark Hive
- apache spark SQL
- apache spark yarn
- apache spark MaxCompute
- apache spark like
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark运行
- apache spark summit
- apache spark集群
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala
- apache spark程序