[帮助文档] 通过Apache Airflow向EMR Severless Spark提交任务
Apache Airflow是一个强大的工作流程自动化和调度工具,它允许开发者编排、计划和监控数据管道的执行。EMR Serverless Spark为处理大规模数据处理任务提供了一个无服务器计算环境。本文为您介绍如何通过Apache Airflow实现自动化地向EMR Serverless Spa...

CentOS部署Apache Superset大数据可视化BI分析工具并实现无公网IP远程访问
前言 Superset是一款由中国知名科技公司开源的“现代化的企业级BI(商业智能)Web应用程序”,其通过创建和分享dashboard,为数据分析提供了轻量级的数据查询和可视化方案。Superset在数据处理和可视化方面具有强大的功能,能够满足企业级的数据分析需求,并为用户提供直观、灵活的数据探索...

一文读懂Apache Beam:统一的大数据处理模型与工具
作为一位热衷于探索和传播大数据技术知识的博主,今天我想为大家揭示Apache Beam这一强大且统一的大数据处理模型与工具的庐山真面目。Apache Beam凭借其抽象化的编程模型、广泛的运行环境支持以及强大的生态集成,正在引领大数据处理进入更加灵活、高效的新时代。接下来,我将从Beam的基本概念、...
Apache Hadoop入门指南:搭建分布式大数据处理平台
作为一名关注大数据技术发展的博主,我深知Apache Hadoop在大数据处理领域的重要地位。本文将带领读者从零开始,了解Hadoop的基本概念、核心组件,以及如何搭建一个简单的分布式大数据处理平台,为初学者开启Hadoop之旅提供实用指导。 一、Hadoop概述 起源与发展:Hadoop起源于Go...
[帮助文档] Apache Kafka Connect远程代码执行漏洞_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
2023年02月08日,Apache发布了一则安全公告,修复了Apache Kafka中存在的一个反序列化漏洞,漏洞编号为CVE-2023-25194。在攻击者可以控制Apache Kafka Connect客户端的情况下,通过SASL JAAS配置和基于SASL的安全协议,在其上创建或修改连接器,...
Apache Spark 的基本概念和在大数据分析中的应用
Apache Spark 是一个开源的分布式计算系统,它旨在处理大规模数据集并提供高性能和易用性。Spark 提供了一个统一的编程模型,可以在多种编程语言中使用,包括 Scala、Java、Python和R。Spark 的主要特点包括: 快速:Spark 使用内存计算技术,可以比传统的批处理系统(如...
介绍 Apache Spark 的基本概念和在大数据分析中的应用。
Spark的基本概念包括:弹性分布式数据集(Resilient Distributed Dataset,简称RDD):它是Spark的核心数据结构,代表分布在集群中的可并行处理的数据集,可以在内存中存储。RDD具有容错能力,即使在节点失败时也可以自动恢复。转换操作(Transformations):...
[帮助文档] 如何使用ApacheHDFS透明缓存加速_EMR on ECS_开源大数据平台 E-MapReduce(EMR)
Apache HDFS透明缓存加速可以利用计算集群的闲置存储资源对远端HDFS集群进行数据缓存,避免了计算集群或服务占用核心集群过多带宽。当HDFS集群和计算集群分离,HDFS集群访问性能不及预期时,您可以通过在计算集群或靠近计算集群的地方缓存数据来进行加速。
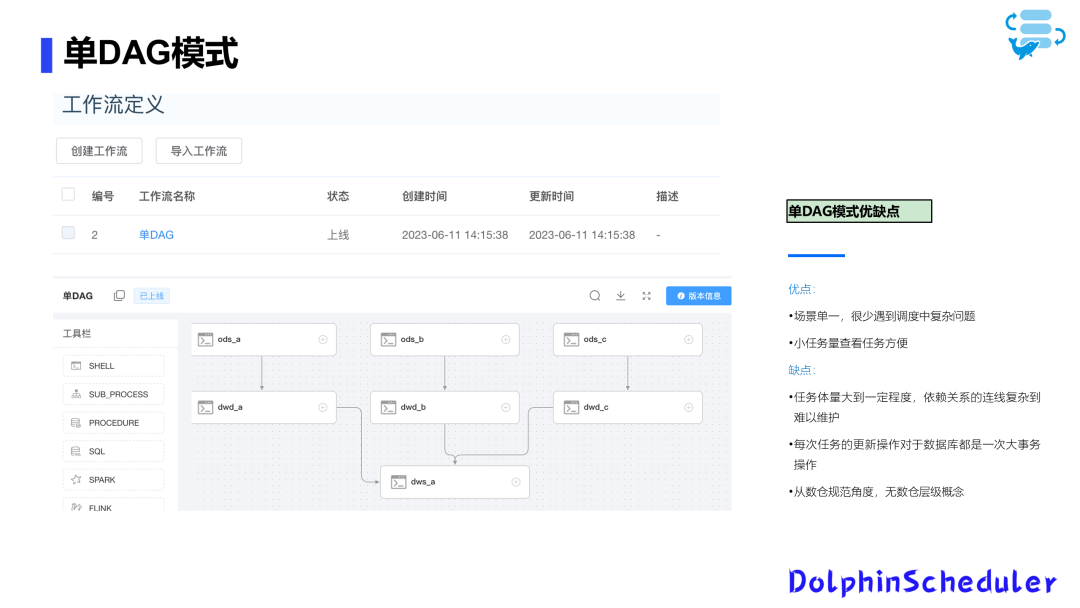
Apache DolphinScheduler 在大数据环境中的应用与调优
本文主要涉及三大主题:首先,探讨常见的工作流配置模式,其次,介绍DS 2.0.X版本的重要功能特性,最后,分享生产环境下的调优实践。01工作流配置模式在Apache DolphinScheduler中,工作流配置模式以其多样性和灵活性而受到开发者喜爱。虽然这些配置模式可能已经为大家所熟知...

大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
一、概述Hudi(Hadoop Upserts Deletes and Incrementals),简称Hudi,是一个流式数据湖平台,支持对海量数据快速更新,内置表格式,支持事务的存储层、 一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具,它可以以极低的延迟将数据快...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。






Apache更多大数据相关
Apache您可能感兴趣
- Apache required
- Apache more
- Apache one
- Apache options
- Apache connect
- Apache实时计算
- Apache报错
- Apache操作
- Apache kafka
- Apache flink
- Apache配置
- Apache rocketmq
- Apache安装
- Apache php
- Apache dubbo
- Apache tomcat
- Apache服务器
- Apache linux
- Apache spark
- Apache开发
- Apache服务
- Apache微服务
- Apache从入门到精通
- Apache doris
- Apache hudi
- Apache mysql
- Apache访问
- Apache日志