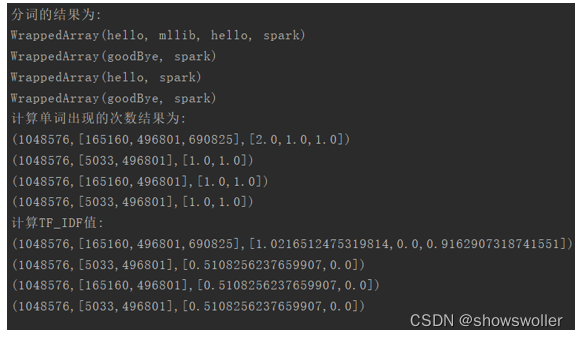
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...
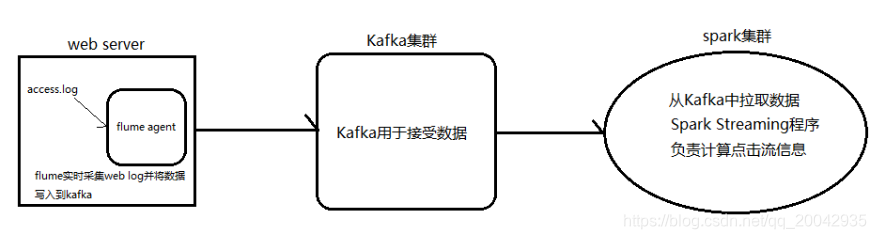
195 Spark Streaming整合Kafka完成网站点击流实时统计
1.安装并配置zk2.安装并配置Kafka3.启动zk4.启动Kafka5.创建topicbin/kafka-topics.sh --create --zookeeper node1.itcast.cn:2181,node2.itcast.cn:2181 \ --replication-factor...


【大数据学习篇10】Spark项目实战~网站转化率统计
学习目标/Target掌握网站转化率统计实现思路了解如何生成用户浏览网页数据掌握如何创建Spark连接并读取数据集掌握利用Spark SQL统计每个页面访问次数 掌握利用Spark SQL获取每个用户浏览网页的顺序掌握利用Spark SQL合并同一用户浏览的网页 掌握利用Spark SQL统计每个单...
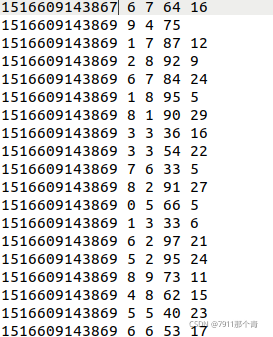
JAVA Spark rdd使用Spark编程实现:统计出每个省份广 告被点击次数的TOP3
假设这些信息都存存储在一个文件里时间数 省份 城市 用户 广告如下所示:(中间字段使用空格隔开)import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.L...
Spark机器学习库(MLlib)指南之简介及基础统计
1.Spark机器学习库(MLlib)指南MLlib是Spark机器学习库,它的目标是使机器学习算法可扩展和易于使用。它提供如下工具:机器学习(ML)算法:常用的学习算法,如分类、回归、聚类和协同过滤特征:特征提取、转化、降维,及选择管道:构造工具、评估工具和调整机器学习管理存储:保存...
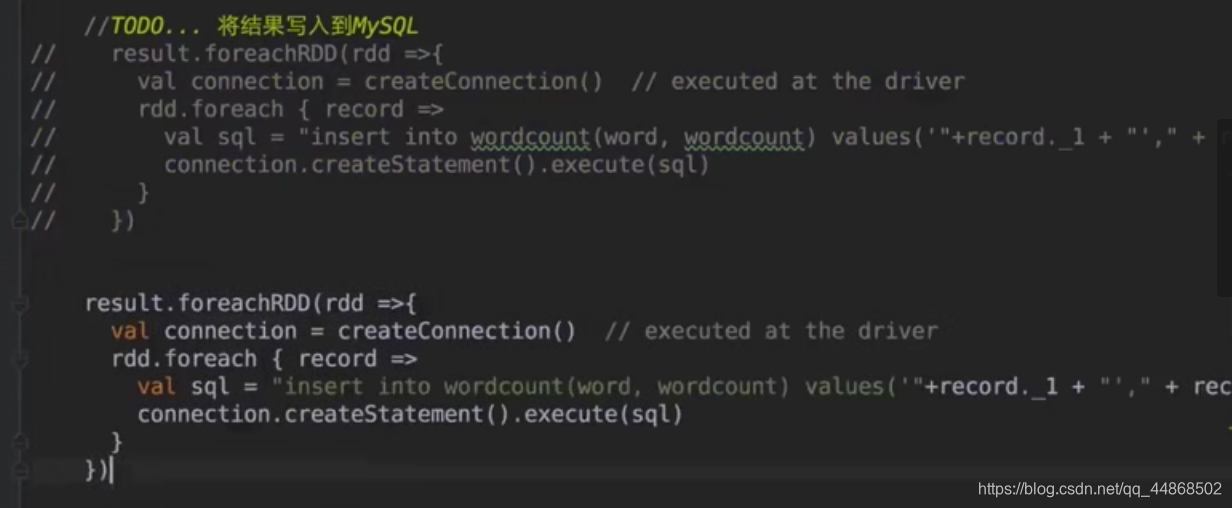
Spark Streaming实时流处理项目实战笔记——将统计结果写入到MySQL数据库中
思路两种方式,一种可优化(foreachRDD后,直接创建连接Mysql),一种在(foreachRDD后通过foreachPartition,通过分区获取)代码实现import java.sql.DriverManager import Spark.UpdateStateByKey....
Spark 机器学习 概括统计 summary statistics [摘要统计]
概括统计 summary statistics [摘要统计]单词linalg 分开linear + algebra: 线性代数对于RDD[Vector]类型的变量,Spark MLlib提供了一种叫colStats()的统计方法,调用该方法会返回一个类型为MultivariateStatistica...
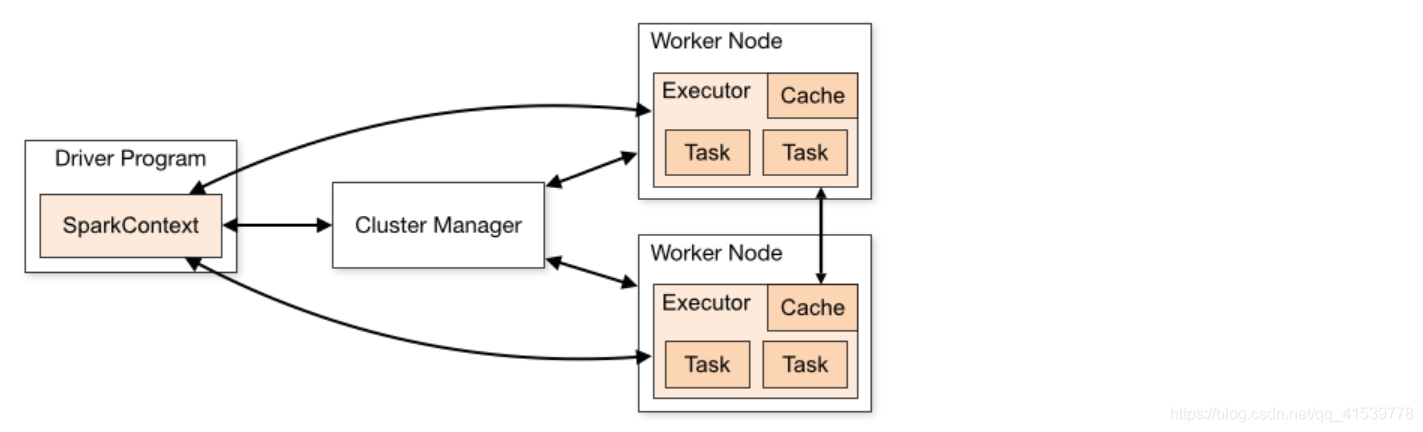
大数据实验——用Spark实现wordcount单词统计
一、实验目的学会启用spark将文本上传到hdfs上在scala模式下编写单词统计二、实验过程了解spark的构成2、具体步骤 1、打开一个终端,启动hadoophadoop@dblab-VirtualBox:/usr/local/hadoop/sbin$ ./start-...

六十四、Spark-分别统计各个单词个数及特殊字符总个数
共享变量广播变量(Broadcast Variables):广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本,简单理解:减少内存,减小计算压力;累加器(Accumulators)ÿ...
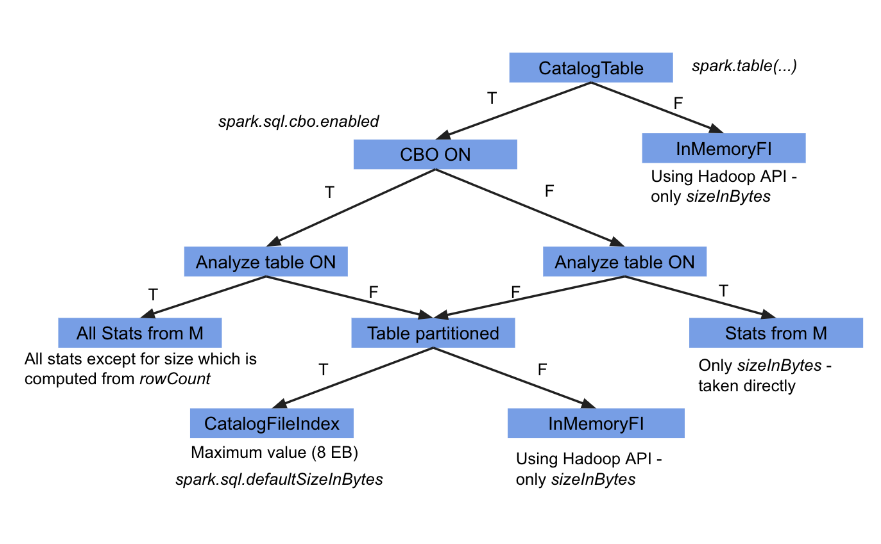
SPARK统计信息的来源-通过优化规则来分析
背景此文的分析基于spark 3.1.2且set spark.sql.catalogImplementation = hive 且表是分区的情况下在之前翻译的文章Spark SQL explaind中的统计信息-深入了解CBO优化里,我们说到,如果一个hive表是分区的,没有开启CBO,没有进行AT...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark更多统计相关
apache spark您可能感兴趣
- apache spark like
- apache spark应用
- apache spark SQL
- apache spark原理
- apache spark产品
- apache spark k8s
- apache spark方案
- apache spark大数据
- apache spark深度学习
- apache spark集群
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark summit
- apache spark模式
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark任务
- apache spark程序