大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和H...
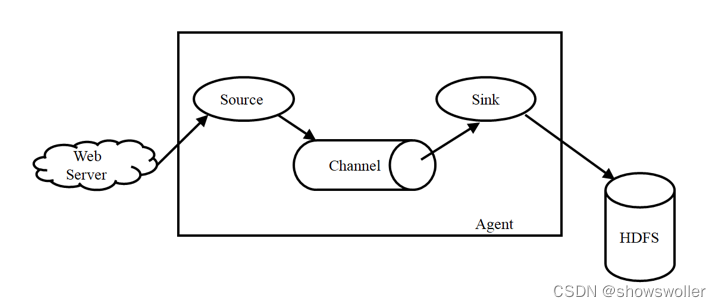
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:...

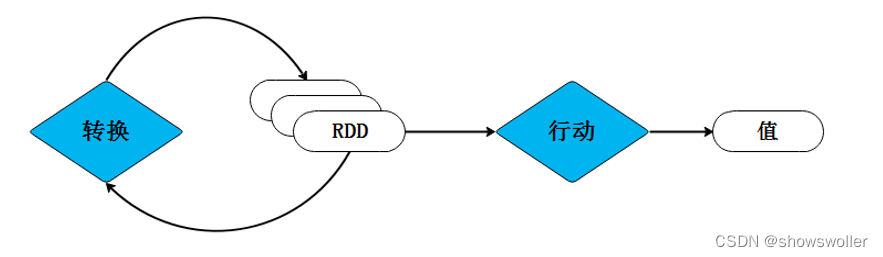
【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建R...
【大数据技术Hadoop+Spark】Spark RDD设计、运行原理、运行流程、容错机制讲解(图文解释)
一、RDD的概念RDD(Resilient Distributed Dataset),即弹性分布式数据集,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并且还能控制数据的分区。不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提高数据处理...
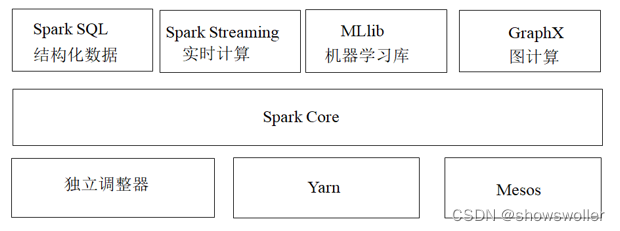
【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心...
【大数据技术Hadoop+Spark】HBase数据模型、Shell操作、Java API示例程序讲解(附源码 超详细)
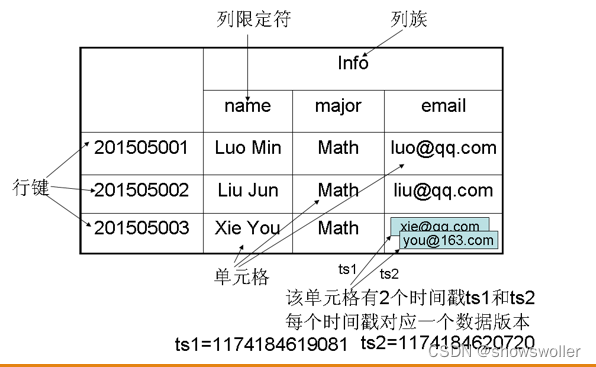
一、HBase数据模型HBase分布式数据库的数据存储在行列式的表格中,它是一个多维度的映射模型,其数据模型如下所示。表的索引是行键,列族,列限定符和时间戳,表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,列族支持动态扩展,可以很轻松的添加一个列族或者列,无须预先定义列的数量及数据...
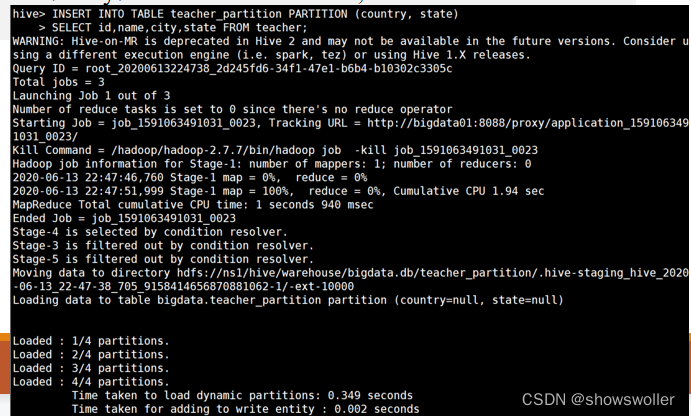
【大数据技术Hadoop+Spark】Hive基础SQL语法DDL、DML、DQL讲解及演示(附SQL语句)
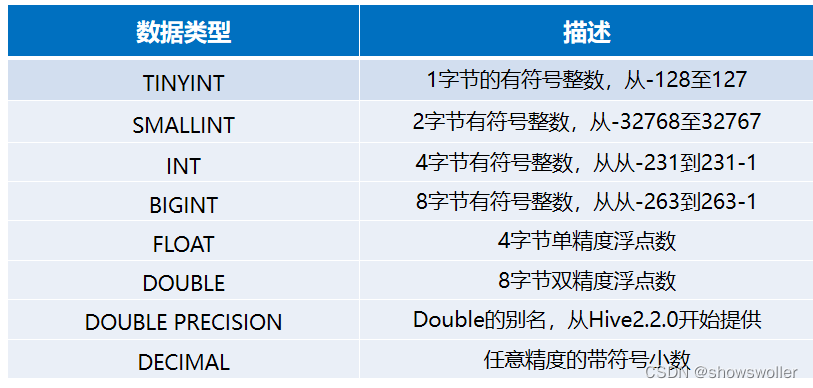
Hive基础SQL语法1:DDL操作DDL是数据定义语言,与关系数据库操作相似,创建数据库CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name显示数据库SHOW databases;查看数据库详情DESC DATABASE|SCHEMA datab...
【大数据技术Hadoop+Spark】Hive数据仓库架构、优缺点、数据模型介绍(图文解释 超详细)
一、Hive简介Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook...
【大数据技术Hadoop+Spark】MapReduce之单词计数和倒排索引实战(附源码和数据集 超详细)
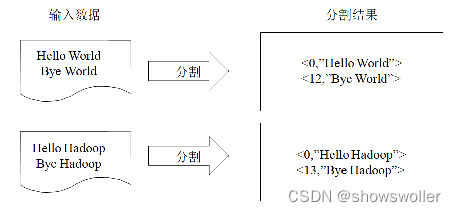
源码和数据集请点赞关注收藏后评论区留言私信~~~一、统计单词出现次数单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World。其主要功能是统计一系列文本文件中每个单词出现的次数程序解析首先MapReduce将文件拆分成splits,由于测试用...
【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
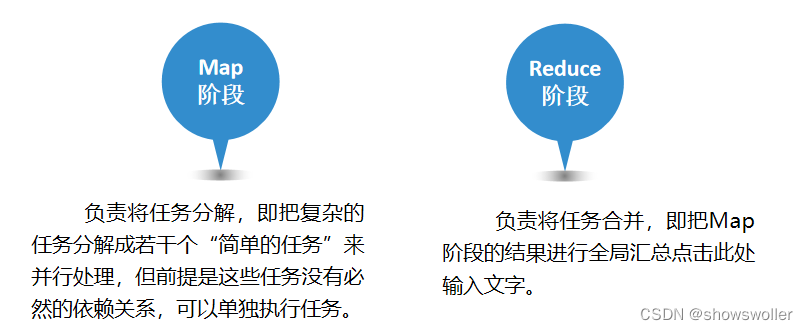
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








