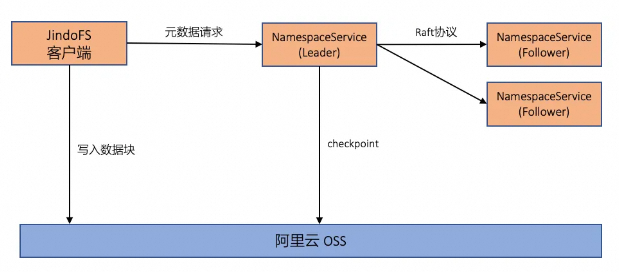
阿里云EMR数据湖文件系统: 面向开源和云打造下一代 HDFS
前言 最近,阿里云EMR重磅推出新版数据湖Datalake,100%兼容社区大数据开源组件,具备极强的弹性能力,支持数据湖构建DLF、对象存储OSS和OSS-HDFS,支持 Delta Lake、Hudi、Iceberg 三种湖格式。结合阿里云DataWorks,可以为用户提供从入湖、建模、开发、调...
[帮助文档] 通过阿里云Milvus与PAI构建大模型RAG对话系统
阿里云Milvus现已无缝集成于阿里云PAI平台,一站式赋能用户构建高性能的检索增强生成(RAG)系统。您可以利用Milvus作为向量数据的实时存储与检索核心,高效结合PAI和LangChain技术栈,实现从理论到实践的快速转化,搭建起功能强大的RAG解决方案。

[帮助文档] 使用pyjindo访问阿里云OSS-HDFS
本文将以两种方式为您介绍如何在Python 3.6及更高版本中,利用Python的工具包pyjindo来操作OSS-HDFS。
[帮助文档] 阿里云账号角色授权
使用EMR Serverless Spark前,需要授予您的阿里云账号AliyunServiceRoleForEMRServerlessSpark和AliyunEMRSparkJobRunDefaultRole系统默认角色。本文为您介绍角色授权的基本操作。
[帮助文档] 通过阿里云Milvus和通义千问快速构建定制知识库问答系统
本文展示了如何使用阿里云向量检索Milvus和灵积(Dashscope)提供的通用千问大模型能力,快速构建一个基于专属知识库的问答系统。在示例中,我们通过接入灵积的通义千问API及文本嵌入(Embedding)API来实现LLM大模型的相关功能。
[帮助文档] 阿里云账号角色授权
使用EMR向量检索Milvus版前,需要授予您的阿里云账号AliyunServiceRoleForMilvus角色。本文为您介绍角色授权的基本操作。
阿里云 EMR Serverless Spark 版免费邀测中
随着大数据应用的广泛推广,企业对于数据处理的需求日益增长。为了进一步优化大数据开发流程,减少企业的运维成本,并提升数据处理的灵活性和效率,阿里云开源大数据平台 E-MapReduce (简称“EMR”)正式推出 EMR Serverless Spark 版,并已开启邀测! 立即申请 以强大的 Spa...
阿里云E-MapReduce中EMR自定义集群 HUE是自带吗 没有看懂啊HUE选项?
阿里云E-MapReduce中EMR自定义集群 HUE是自带吗 没有看懂啊HUE选项?
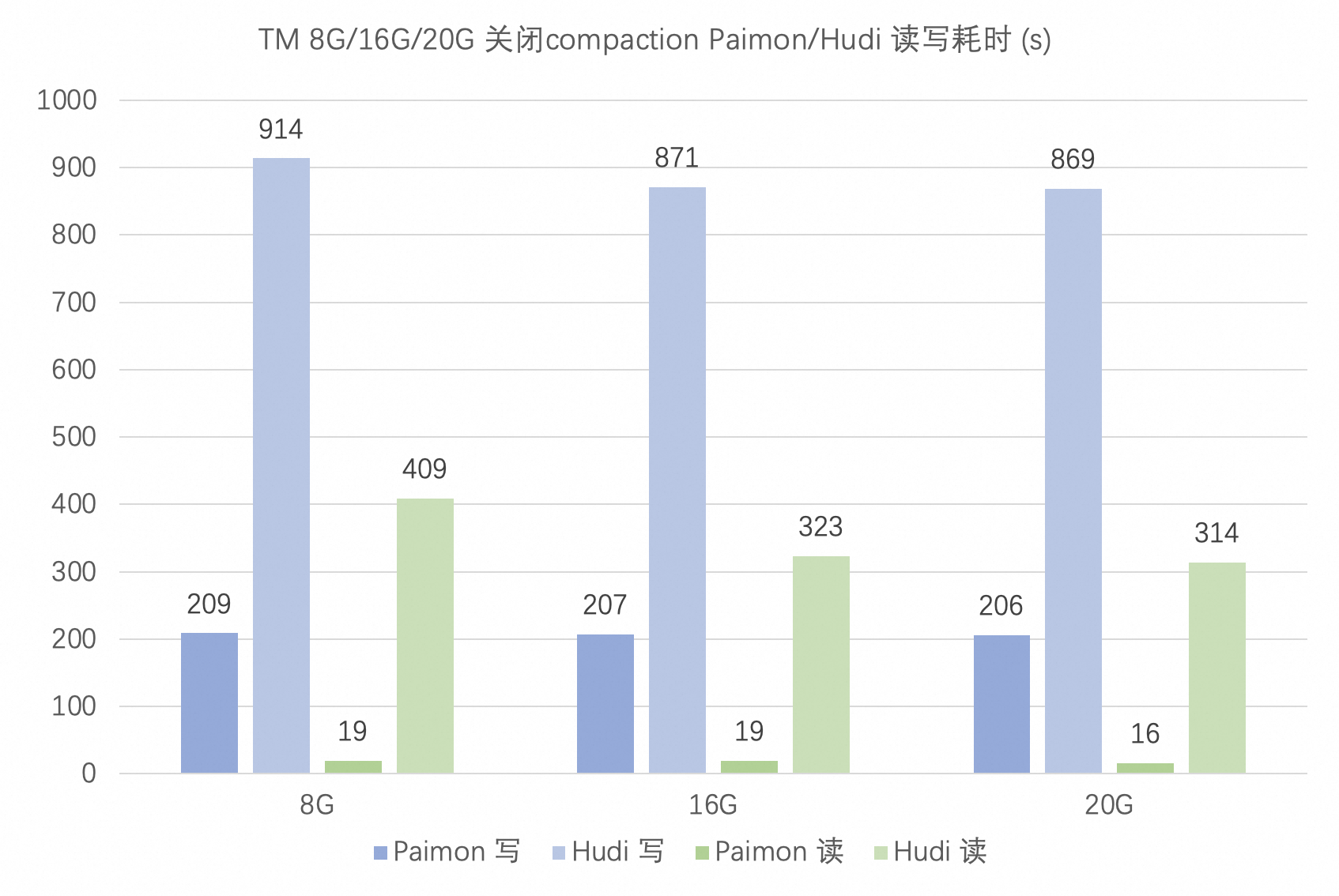
阿里云 EMR 基于 Paimon 和 Hudi 构建 Streaming Lakehouse
作者:邹欣宇@阿里云背景信息数据湖与传统的数据仓库相比,可以更灵活地处理各种类型的数据,并支持高度可扩展的存储,通常被用于大数据分析。为了支持准实时乃至实时的数据处理,数据湖需要能够快速地接收和存储数据(数据入湖),同时提供低延迟的查询性能以满足分析需求。Apache Paimon 和 Apache...
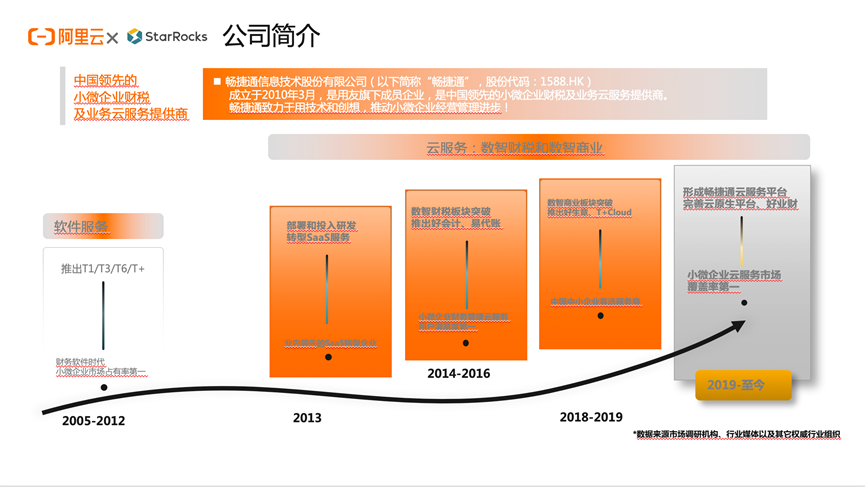
用友畅捷通基于阿里云 EMR StarRocks 搭建实时湖仓实战分享
作者:王龙强 用友畅捷通数据架构师,主要负责公司数据链路架构设计、数据质量、链路稳定性等工作。本文将围绕以下五个方面展开:公司简介业务背景技术选型案例分享未来发展一、公司简介用友畅捷通是中国领先的小微企业财税及业务云服务提供商,公司成立于2010年,是用友旗下成员企业,致力于用技术和创...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









