Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(二)
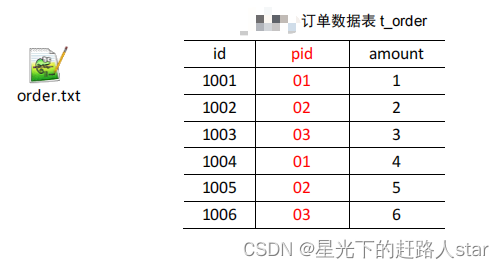
3、Join应用3.1 Reduce Join(1)Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。(2)Reduce端的主要工作:在Reduce端以连接...
Hadoop学习---7、OutputFormat数据输出、MapReduce内核源码解析、Join应用、数据清洗、MapReduce开发总结(一)
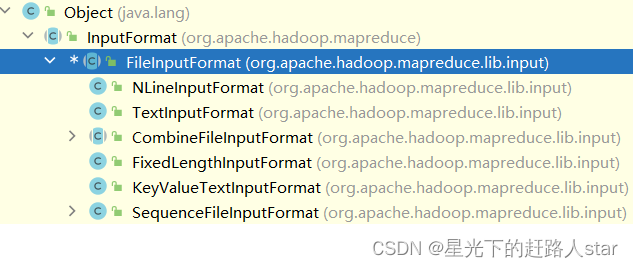
1、OutputFormat数据输出1.1 OutputFormat接口实现类OutputFormat是MapReduce输出的基类,所以实现MapReduce输出都实现了OutputFormat接口。1、MapReduce默认的输出格式是TextOutputFormat2、也可以自定义Output...
Hadoop基础学习---6、MapReduce框架原理(二)
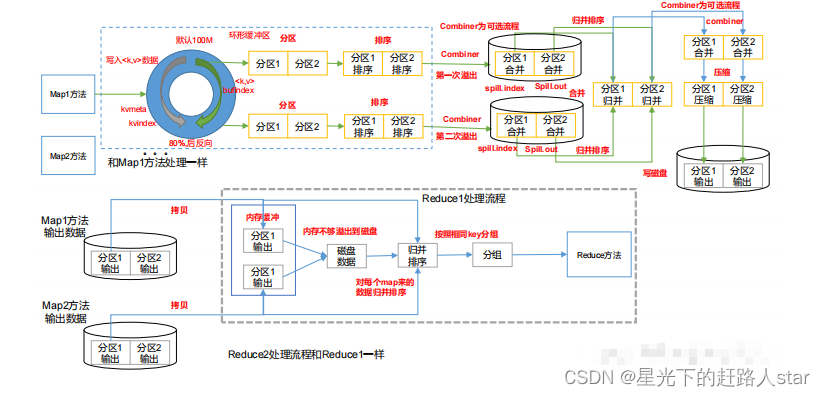
1.3 Shuffle机制1.3.1 Shuffle机制Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。1.3.2 Partition1、问题引出要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照收集归属地不同省份输出到不同文件中。2、默认Partition...
Hadoop基础学习---6、MapReduce框架原理(一)
1、MapReduce框架原理1.1 InputFormat数据输入1.1.1 切片与MapTask并行度决定机制1、问题引出MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个job的处理速度。2、MapTask并行度决定机制数据块:Block是HDFS物理上吧数据分成一块一块。数...
Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、Hadoop序列化
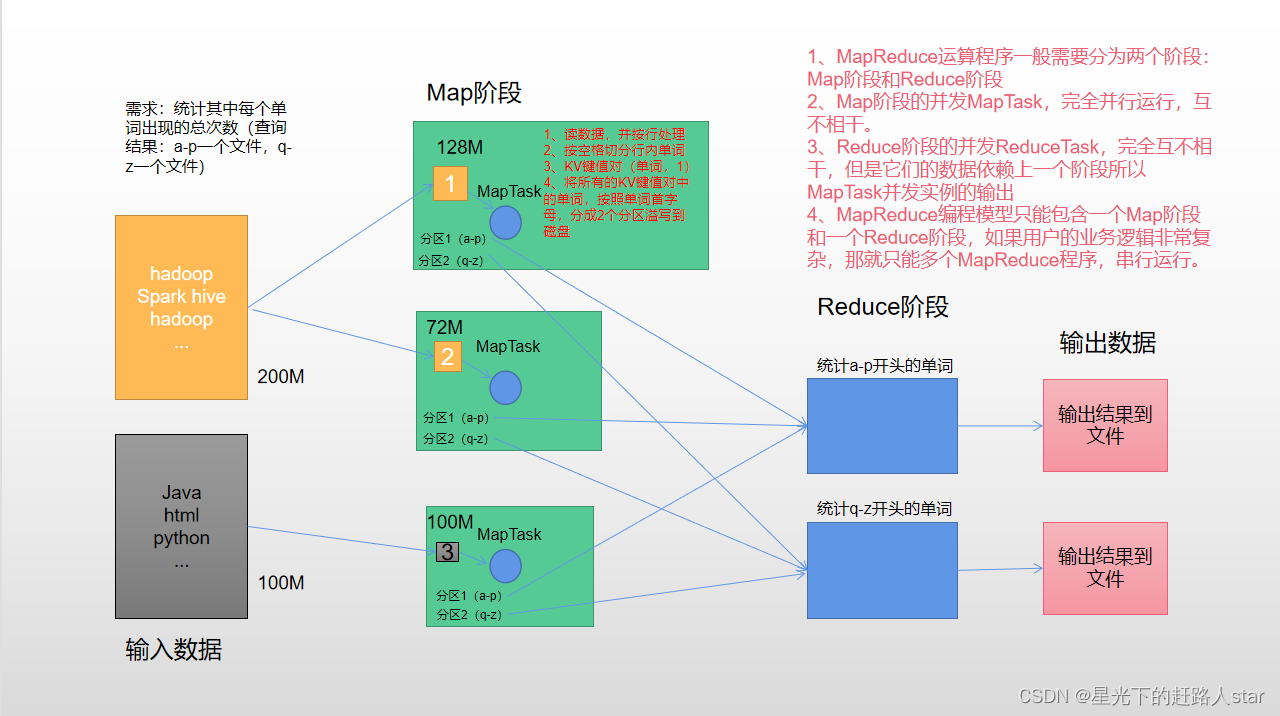
1、MapReduce概述1.1 MapReduce定义MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。1.2...
Hadoop生态系统中的数据处理技术:MapReduce的原理与应用
Hadoop生态系统是大数据处理的核心框架之一。在Hadoop生态系统中,MapReduce是一种常用的数据处理技术。本文将介绍MapReduce的原理和应用,并提供代码示例。 一、MapReduce的原理 MapReduce是一种分布式计算模型,用于处理大规模数据集。它的原理可以简单概括为“分而治...
阿里云E-MapReduce的那hadoop sdk怎么拿到?maven里没有。
阿里云E-MapReduce的那hadoop sdk怎么拿到?maven里没有。
【Hadoop】一个例子带你了解MapReduce
一、前期准备1. 运行环境想要运行WordCount程序,其实可以不需要安装任何的Hadoop软件环境,因为实际上执行计算任务的是Hadoop框架集成的各种jar包。Hadoop启动后的各项进程主要用于支持HDFS的使用,各个节点间的通讯,任务调度等等。所以如果我们只是想测试程序的可用性的话可以只新...
hadoop之MapReduce
一个与Hadoop开发相关的知识点是MapReduce。MapReduce是一种分布式处理模型,可用于大规模数据集的处理和计算,在Hadoop中被广泛应用。在本文中,我将详细介绍什么是MapReduce,如何实现和使用它,并提供代码示例以加深您对该技术的理解。 什么是MapReduce? MapRe...
Hadoop知识点总结——MapReduce的Shuffle
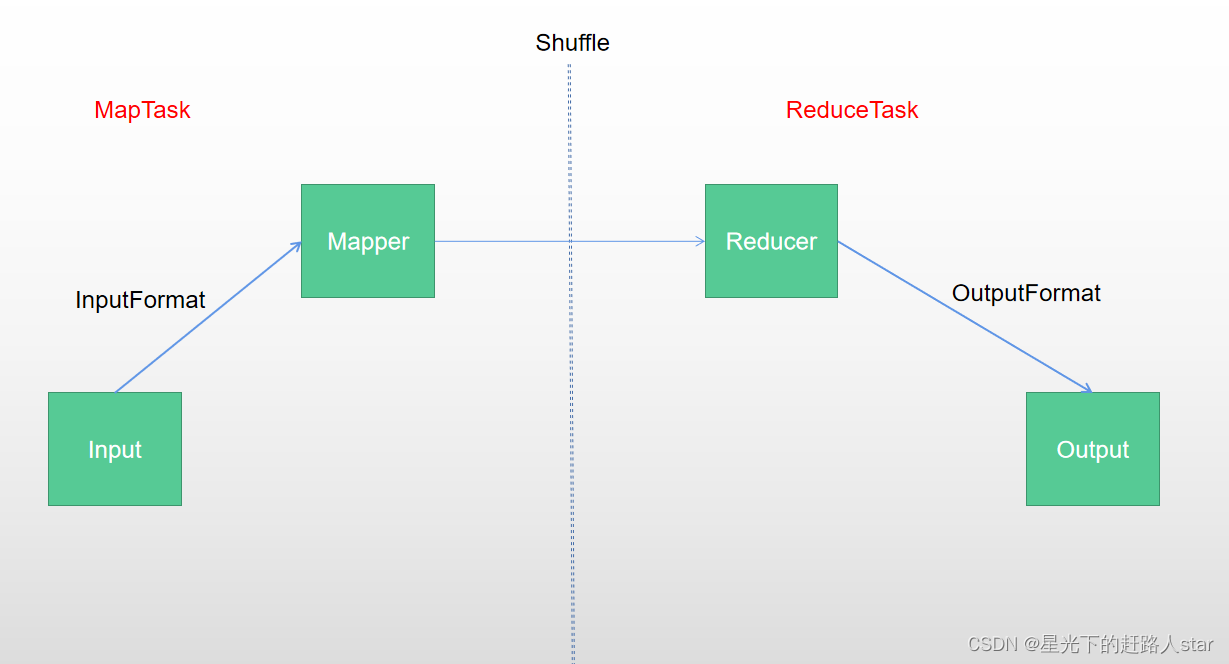
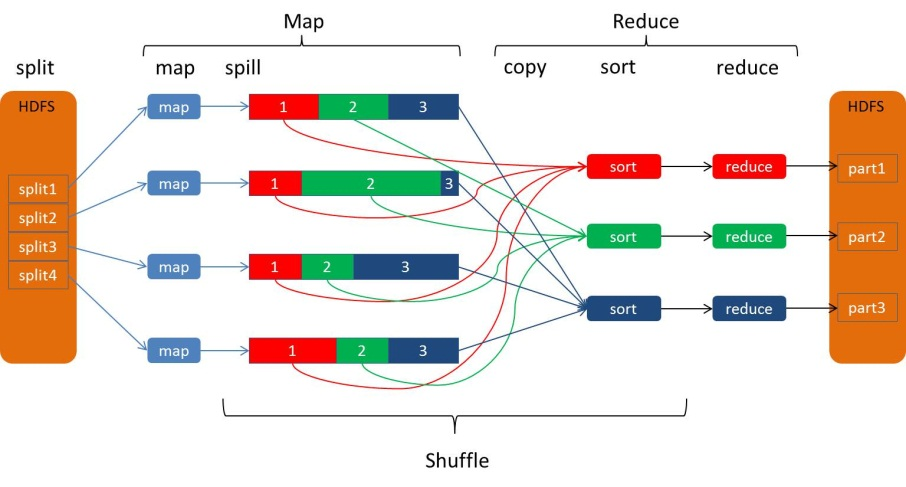
Hadoop学习之路(二十三)MapReduce中的shuffle详解 <= 以下内容出自该博客 从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子

开源大数据平台 E-MapReduce更多hadoop相关
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce访问
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce实践
- 开源大数据平台 E-MapReduce ecs
- 开源大数据平台 E-MapReduce服务器
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce emr
- 开源大数据平台 E-MapReduce机器
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce信息
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce程序
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce map