大数据存储技术(1)—— Hadoop简介及安装配置
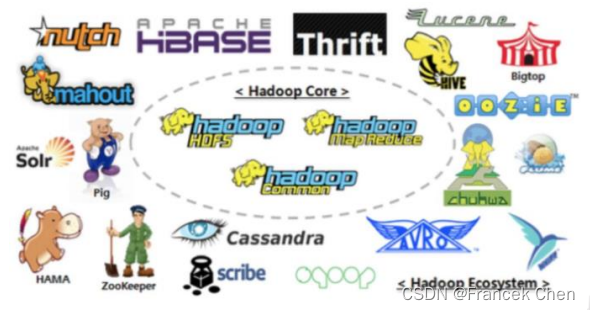
一、Hadoop简介 (一)概念 1、Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 2、主要解决,海量数据的存储和海量数据的分析计算问题。 3、广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。 ...
【大数据】Hadoop技术解析:大数据处理的核心引擎
**引言:**在当今的信息时代,大数据已经成为商业和科学研究的关键资源。然而,处理和分析大数据集是一个庞大而复杂的任务。在这个挑战性领域,Hadoop已经崭露头角,它是一个开源的分布式数据处理框架,为处理大规模数据集提供了强大的工具。本文将深入探讨Hadoop的核心概念、架构、应用领域,并提供示例代...

Hadoop依赖的技术基础
Hadoop依赖的技术基础3.1 Java编程基础Hadoop以及其他大数据处理技术很多都是用JavaAPI开发的,因此学习Hadoop的一个首要条件,就是必须掌握Java语言编程·Java语言基础 主要掌握Java语言的基本数据类型、运算符与表达式以及语句与控制结构 ...
Hadoop生态系统中的云计算与容器化技术:Apache Mesos和Docker的应用
Hadoop生态系统中的云计算与容器化技术:Apache Mesos和Docker的应用 引言:在当今大数据时代,Hadoop生态系统已经成为处理大规模数据的标准工具。然而,传统的Hadoop集群管理方式存在一些问题,例如资源利用率低、维护困难等。为了解决这些问题,云计算和容器化技术成为了Hadoo...
Hadoop生态系统中的资源管理与调度技术:YARN的原理与应用案例
Hadoop生态系统中的资源管理与调度技术:YARN的原理与应用案例 Hadoop是一个开源的分布式计算框架,它提供了一种可扩展的,分布式存储和处理大规模数据集的能力。Hadoop生态系统中的资源管理与调度技术是实现高效的资源利用和任务调度的关键。其中,YARN(Yet Another Resour...
Hadoop生态系统中的数据可视化技术:Apache Zeppelin和Apache Superset的比较
Hadoop生态系统中的数据可视化技术是帮助用户更好地理解和分析大数据的重要工具。在这篇文章中,我们将比较两个主要的数据可视化工具:Apache Zeppelin和Apache Superset。 Apache Zeppelin是一个基于Web的交互式数据分析和可视化工具。它支持多种编程语言,包括S...
Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较
Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较 引言:在大数据时代,处理海量的实时数据变得愈发重要。Hadoop生态系统中的两个主要的流式数据处理框架,Apache Flink和Apache Spark,都提供了强大的功能来应对这一挑战。本文将对这...
Hadoop生态系统中的实时数据处理技术:Apache Kafka和Apache Storm的应用
Hadoop生态系统是一个开源的分布式计算和存储平台,它提供了各种工具和技术来处理大规模数据集。其中,实时数据处理是一个重要的应用场景,它可以帮助企业实时地处理和分析海量数据,以及快速做出决策。在Hadoop生态系统中,Apache Kafka和Apache Storm是两个常用的实时数据处理技术。...
Hadoop生态系统中的数据查询与分析技术:Hive和Pig的比较与应用场景
Hadoop是一个开源的分布式计算平台,用于存储和处理大规模数据集。它的生态系统中有许多数据查询和分析技术,其中Hive和Pig是两个常用的工具。本文将从比较和应用场景两个方面介绍Hive和Pig。 首先,我们来看一下Hive。Hive是一个基于Hadoop的数据仓库工具,它允许用户使用类似于SQL...
Hadoop生态系统中的数据处理技术:MapReduce的原理与应用
Hadoop生态系统是大数据处理的核心框架之一。在Hadoop生态系统中,MapReduce是一种常用的数据处理技术。本文将介绍MapReduce的原理和应用,并提供代码示例。 一、MapReduce的原理 MapReduce是一种分布式计算模型,用于处理大规模数据集。它的原理可以简单概括为“分而治...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








