
伪分布式安装部署(运行MapReduce程序)
启动HDFS并运行MapReduce程序1. 配置集群(a)配置:hadoop-env.shLinux系统中获取JDK的安装路径:echo $JAVA_HOME修改JAVA_HOME 路径: 把这一行代码改成下面的代码,前一半都是export JAVA_HOME=,很好找。export J...
MapReduce 程序
如何使用 Java API 来编写一个简单的 MapReduce 程序来统计文本文件中每个单词出现的次数。 首先,我们需要了解 MapReduce 模型的基本原理。MapReduce 将数据处理分为两个阶段:Map 和 Reduce。在 Map 阶段中,我们将输入的数据拆分成若干个键值对,并对这些键...
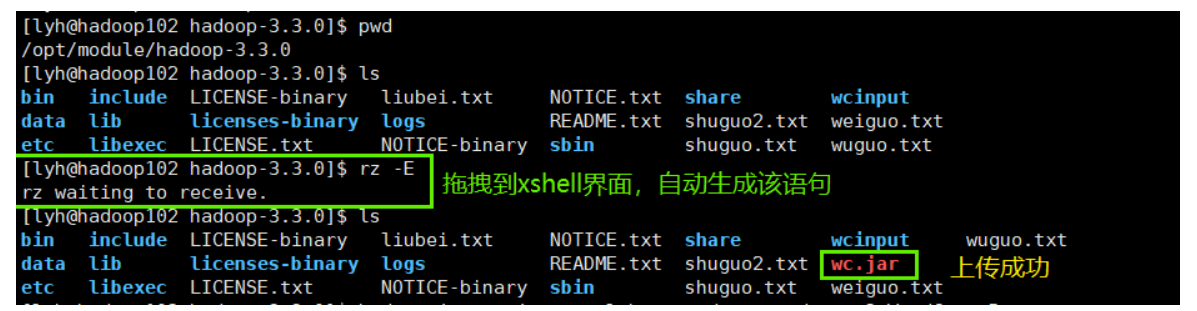
【集群模式】执行MapReduce程序-wordcount
因为是在hadoop集群下通过jar包的方式运行我们自己写的wordcount案例,所以需要传递的是 HDFS中的文件路径,所以我们需要修改上一节【本地模式】中 WordCountRunner类 的代码://5.设置统计文件输入的路径,将命令行的第一个参数作为输入文件的路径 FileInputFor...
【本地模式】第一个Mapreduce程序-wordcount
【本地模式】:也就是在windows环境下通过hadoop-client相关jar包进行开发的,我们只需要通过本地自己写好MapReduce程序即可在本地运行。一个Maprduce程序主要包括三部分:Mapper类、Reducer类、执行类。map阶段:将每一行单词提取出来转为map(key,1)的...
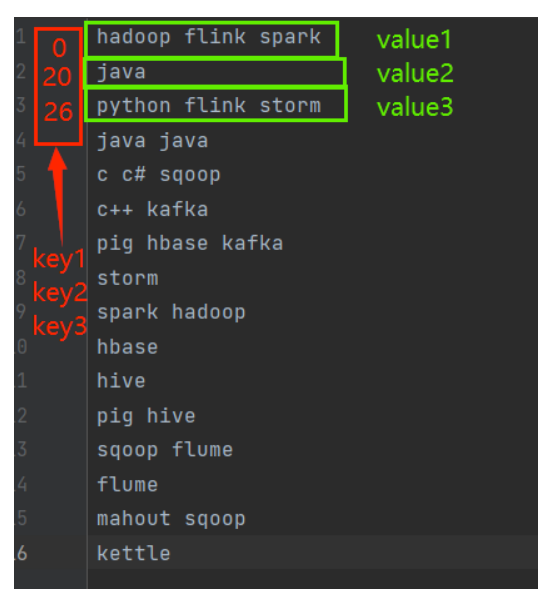
有一个日志文件visitlog.txt,其中记录了用户访问网站的日期和访问的网站地址信息,每行一条记录。要求编写mapreduce程序完成以下功能: 1、 将不同访问日期的访问记录分配给不同的red
题目描述:有一个日志文件visitlog.txt,其中记录了用户访问网站的日期和访问的网站地址信息,每行一条记录。要求编写mapreduce程序完成以下功能:1、 将不同访问日期的访问记录分配给不同的reduce task(假设只有3个不同日期),而且结果要按照网站网址的字典序降序排序2、 以1)的...
动手写的第一个MapReduce程序--wordcount
引语: 之前运行过了hadoop官方自带的第一个例子wordcount,这次我们自己手写一个,这个相当于是编程语言中的helloworld一样.首先我们了解一下我们要写的MapReduce是处理的哪个部分,我们知道hadoop处理文件是先将要处理的文件拆...

Apache Oozie-- 实战操作--集成 hue& 调度 mapreduce 程序|学习笔记
开发者学堂课程【Oozie 知识精讲与实战演练:Apache Oozie-- 实战操作--集成 hue& 调度 mapreduce 程序】学习笔记,与课程紧密联系,让用户快速学习知识。 课程地址:https://developer.aliyun.com/learning/course/716...
Apache Oozie-- 实战操作--调度 mapreduce 程序|学习笔记
开发者学堂课程【Oozie 知识精讲与实战演练:Apache Oozie-- 实战操作--调度 mapreduce 程序】学习笔记,与课程紧密联系,让用户快速学习知识。 课程地址:https://developer.aliyun.com/learning/course/716/detai...
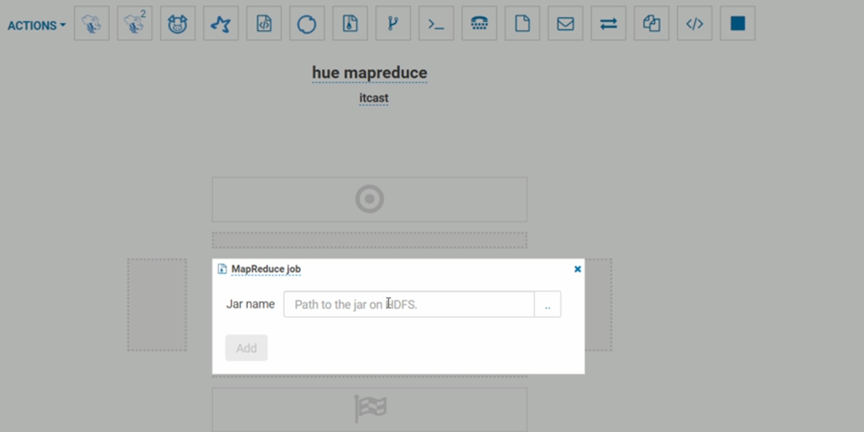
集成 Oozie 服务&调度 Mapreduce 程序 | 学习笔记
开发者学堂课程【Hue 大数据可视化终端课程:集成 Oozie 服务&调度 Mapreduce 程序】学习笔记,与课程紧密联系,让用户快速学习知识。课程地址:https://developer.aliyun.com/learning/course/719/detail/12855集成...
第一个MapReduce程序-------WordCount
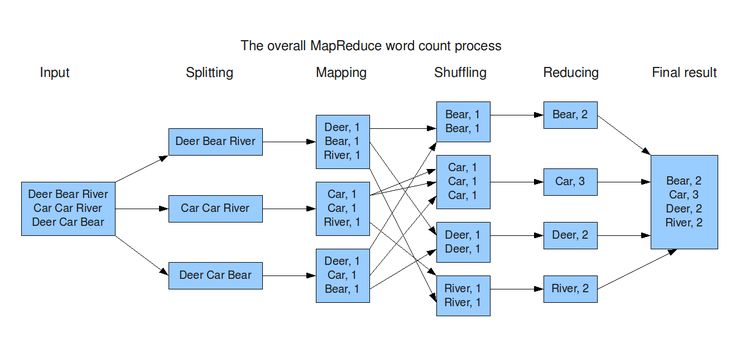
本关任务词频统计是最能体现MapReduce思想的程序,结构简单,上手容易。词频统计的大致功能是:统计单个或者多个文本文件中每个单词出现的次数,并将每个单词及其出现频率按照<k,v>键值对的形式输出,其基本执行流程如下图所示:由图可知:输入文本(可以不只一个&...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
社区圈子

开源大数据平台 E-MapReduce更多程序相关
开源大数据平台 E-MapReduce您可能感兴趣
- 开源大数据平台 E-MapReduce访问
- 开源大数据平台 E-MapReduce报错
- 开源大数据平台 E-MapReduce实践
- 开源大数据平台 E-MapReduce ecs
- 开源大数据平台 E-MapReduce服务器
- 开源大数据平台 E-MapReduce集群
- 开源大数据平台 E-MapReduce emr
- 开源大数据平台 E-MapReduce机器
- 开源大数据平台 E-MapReduce任务
- 开源大数据平台 E-MapReduce信息
- 开源大数据平台 E-MapReduce hadoop
- 开源大数据平台 E-MapReduce数据
- 开源大数据平台 E-MapReduce编程
- 开源大数据平台 E-MapReduce maxcompute
- 开源大数据平台 E-MapReduce运行
- 开源大数据平台 E-MapReduce作业
- 开源大数据平台 E-MapReduce spark
- 开源大数据平台 E-MapReduce yarn
- 开源大数据平台 E-MapReduce框架
- 开源大数据平台 E-MapReduce排序
- 开源大数据平台 E-MapReduce wordcount
- 开源大数据平台 E-MapReduce api
- 开源大数据平台 E-MapReduce优化
- 开源大数据平台 E-MapReduce入门
- 开源大数据平台 E-MapReduce案例
- 开源大数据平台 E-MapReduce map