线程的内核元数据会消耗多少内存?
线程的内核元数据会消耗多少内存?
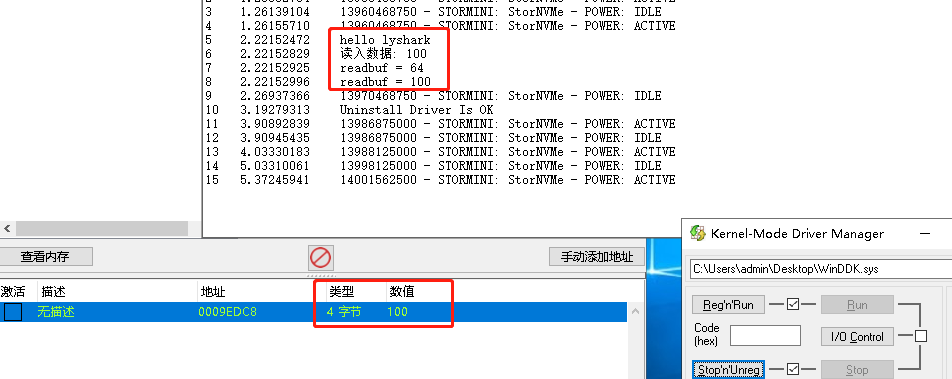
3.2 Windows驱动开发:内核CR3切换读写内存
CR3是一种控制寄存器,它是CPU中的一个专用寄存器,用于存储当前进程的页目录表的物理地址。在x86体系结构中,虚拟地址的翻译过程需要借助页表来完成。页表是由页目录表和页表组成的,页目录表存储了页表的物理地址,而页表存储了实际的物理页框地址。因此,页目录表的物理地址是虚拟地址翻译的关键之一。 在操作...

容器化利器!SysOM 从内核的视角观测内存"黑洞"|龙蜥技术
文/龙蜥社区系统运维SIG01 背景容器化现阶段已经是构建企业 IT 架构的最佳实践。云原生容器化的部署架构,相较于传统 IDC 部署架构的 IT 架构方案,已经成为兼具高效运维及成本控制的业界事实标准。但容器化带来的都是好处么?容器化屏蔽了 IDC 基础设施和云资源的同时,也带来了容器引...
探索Linux内核内存伙伴算法:优化系统性能的关键技术!
通常情况下,一个高级操作系统必须要给进程提供基本的、能够在任意时刻申请和释放任意大小内存的功能,就像malloc 函数那样,然而,实现malloc 函数并不简单,由于进程申请内存的大小是任意的,如果操作系统对malloc 函数的实现方法不对,将直接导致一个不可避免的问题,那就是内存碎片...
[帮助文档] 捕获内核内存污染问题(KFENCE)
Alibaba Cloud Linux 3在内核版本5.10.84-10(x86架构)和5.10.134-16(ARM架构)开始支持KFENCE功能。本文为您介绍KFENCE的功能和使用方法等。
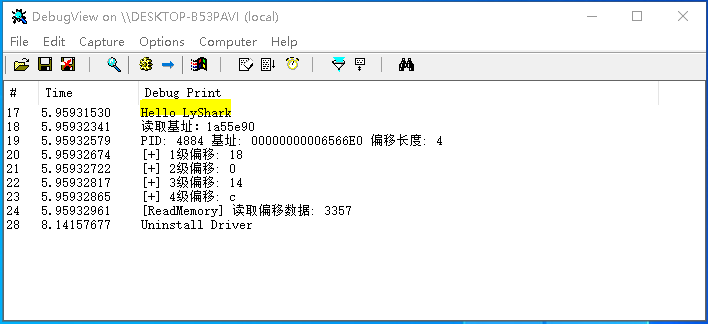
驱动开发:内核读写内存多级偏移
让我们继续在《内核读写内存浮点数》的基础之上做一个简单的延申,如何实现多级偏移读写,其实很简单,读写函数无需改变,只是在读写之前提前做好计算工作,以此来得到一个内存偏移值,并通过调用内存写入原函数实现写出数据的目的。 以读取偏移内存为例,如下代码同样来源于本人的LyMemory读写驱动项目,其中核心...

驱动开发:内核读写内存浮点数
如前所述,在前几章内容中笔者简单介绍了内存读写的基本实现方式,这其中包括了CR3切换读写,MDL映射读写,内存拷贝读写,本章将在如前所述的读写函数进一步封装,并以此来实现驱动读写内存浮点数的目的。内存浮点数的读写依赖于读写内存字节的实现,因为浮点数本质上也可以看作是一个字节集,对于单精度浮点数来说这...
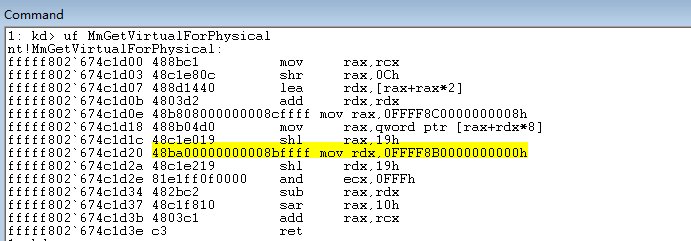
驱动开发:内核解析内存四级页表
当今操作系统普遍采用64位架构,CPU最大寻址能力虽然达到了64位,但其实仅仅只是用到了48位进行寻址,其内存管理采用了9-9-9-9-12的分页模式,9-9-9-9-12分页表示物理地址拥有四级页表,微软将这四级依次命名为PXE、PPE、PDE、PTE这四项。 关于内存管理和分页模式,不同的操作系...
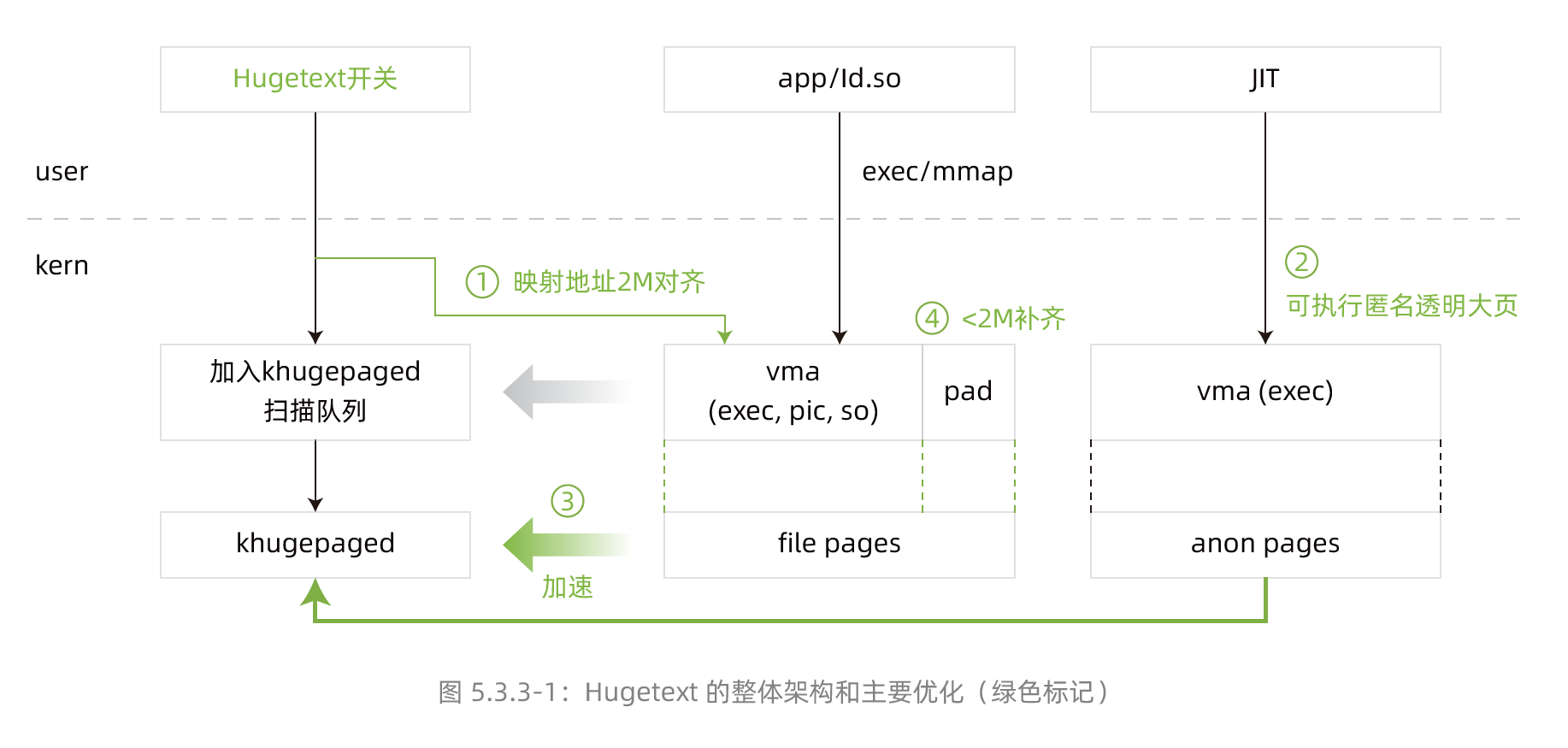
《2022龙蜥社区全景白皮书》——05 原生技术概览——5.3 内核技术——5.3.4 跨处理器节点内存访问优化
5.3.3 数据库/JAVA等高性能场景中的内存优化 背景概述 在处理器内存缓存层级结构中,iTLB miss性能指标对访存优化至关重要,并且在ARM平台上优化效果更为明显。 在数据库/JAVA 等高性能场景中,iTLB miss可以成为影响性能的主要因素,我们通过实验观察到iTLB miss引入的...
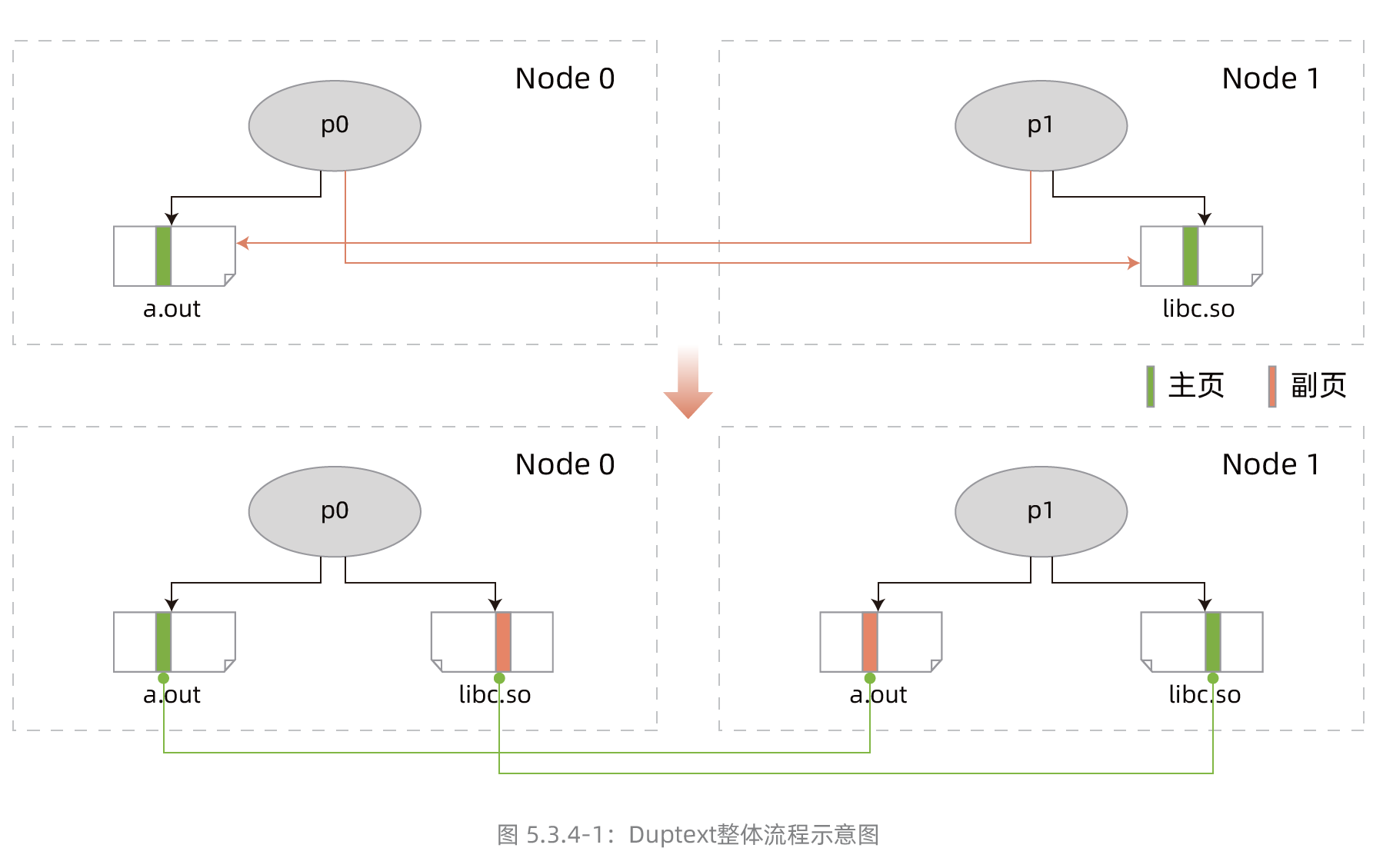
《2022龙蜥社区全景白皮书》——05 原生技术概览——5.3 内核技术——5.3.4 跨处理器节点内存访问优化
5.3.4 跨处理器节点内存访问优化背景概述 在新平台多节点大内存的趋势背景下,打开NUMA是必要的性能手段。随之而来的问题是,跨NUMA访问会引入性能开销。业务一 般配合用户态任务调度,利用绑核等手段规避跨NUMA访问。但文件页跨节点访问不能很好解决。其中,代码段文件页跨节点访问 性能影响比较明显...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐


最佳实践


