Flink CDC里有没有用cdc 和spark hudi集成的?
Flink CDC里有没有用cdc 和spark hudi集成的?
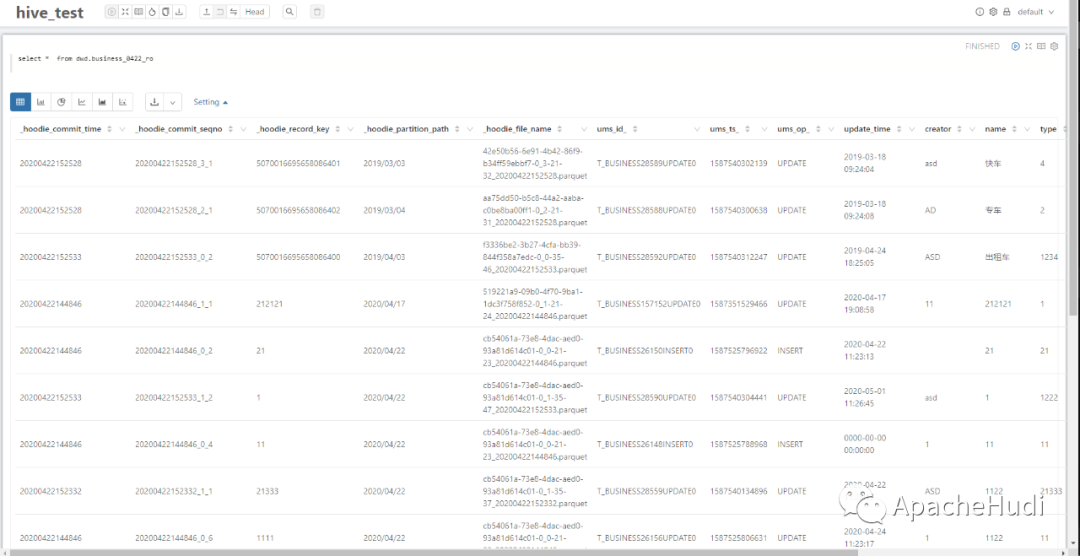
生态 | Apache Hudi集成Apache Zeppelin
1. 简介 Apache Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、...

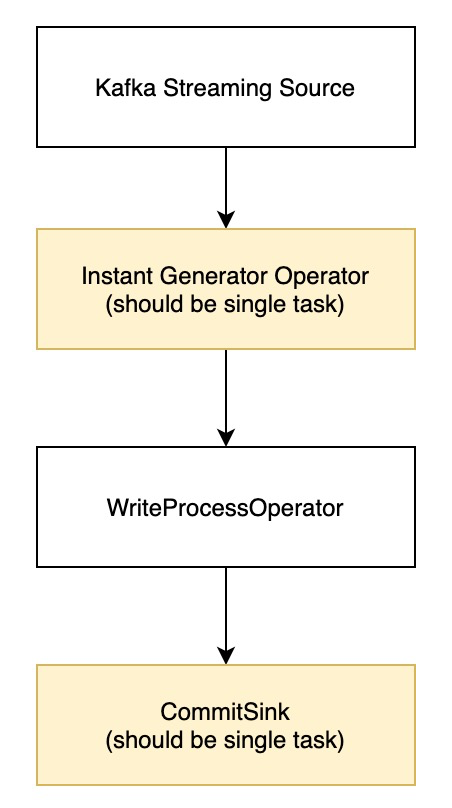
Apache Hudi与Apache Flink更好地集成,最新方案了解下?
1. 现有架构 现有Flink写Hudi架构如下 现有的架构存在如下瓶颈 •InstantGeneratorOperator并发度为1,将限制高吞吐的消费,因为所有的split都将会打到一个线程内,网络IO会...
Apache Hudi与Hive集成手册
1. Hudi表对应的Hive外部表介绍 Hudi源表对应一份HDFS数据,可以通过Spark,Flink 组件或者Hudi客户端将Hudi表的数据映射为Hive外部表,基于该外部表, Hive可以方便的进行实时视图,读优化视图以及增量视图的查询。 2. Hive对Hudi的集成 这里以Hive3....
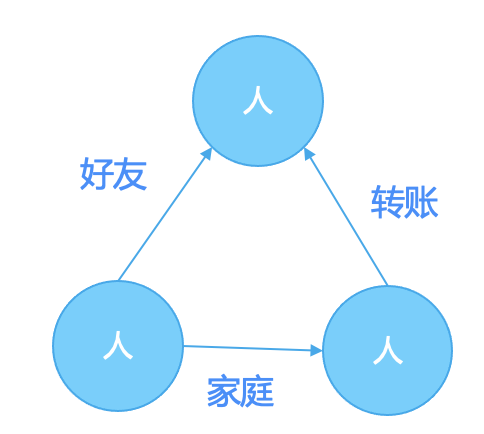
图加速数据湖分析-GeaFlow和Apache Hudi集成
表模型现状与问题 关系模型自1970年由埃德加·科德提出来以后被广泛应用于数据库和数仓等数据处理系统的数据建模。关系模型以表作为基本的数据结构来定义数据模型,表为二维数据结构,本身缺乏关系的表达能力,关系的运算通过Join关联运算来处理。表模型简单且易于理解,在关系模型中被广泛使用。随着互联网信息技...
[帮助文档] Hudi与SparkSQl集成后支持哪些建表语句
本文为您介绍Hudi与Spark SQl集成后,支持的建表语句。
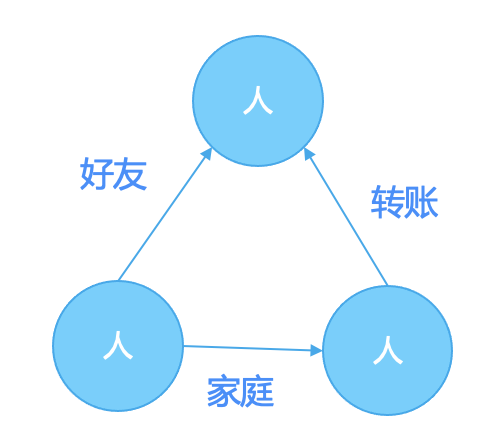
图加速数据湖分析-GeaFlow和Hudi集成
GeaFlow(品牌名TuGraph-Analytics) 已正式开源,欢迎大家关注!!! 欢迎给我们 Star 哦! GitHubhttps://github.com/TuGraph-family/tugraph-analytics更多精彩内容,关注我们的博客 https://geaflow.gi...
[帮助文档] 如何通过SparkSQL对Hudi进行读写操作
E-MapReduce的Hudi 0.8.0版本支持Spark SQL对Hudi进行读写操作,可以极大的简化Hudi的使用成本。本文为您介绍如何通过Spark SQL对Hudi进行读写操作。
E-MapReduce如何实现Hudi与Spark SQL集成
E-MapReduce如何实现Hudi与Spark SQL集成
[帮助文档] Hudi与SparkSQl集成后支持哪些DML语句
本文为您介绍Hudi与Spark SQl集成后,支持的DML语句。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








