CDC一键入湖:当 Apache Hudi DeltaStreamer 遇见 Serverless Spark
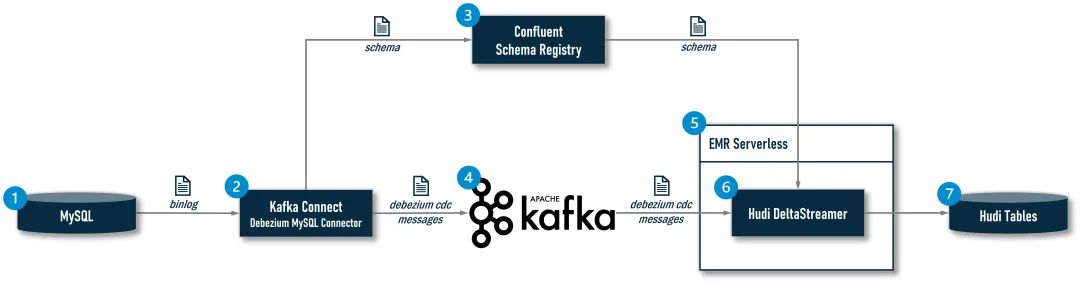
Apache Hudi的DeltaStreamer是一种以近实时方式摄取数据并写入Hudi表的工具类,它简化了流式数据入湖并存储为Hudi表的操作,自 0.10.0 版开始,Hudi又在DeltaStreamer的基础上增加了基于Debezium的CDC数据处理能力,这使得其可以直接将Debeziu...
容器服务ASK有 apache/spark:v3.1.2的可用镜像源吗? 官方只给到3.1.3
容器服务ASK有 apache/spark:v3.1.2的可用镜像源吗? 官方只给到3.1.3

流数据湖平台Apache Paimon(六)集成Spark之DML插入数据
4.4. 插入数据INSERT 语句向表中插入新行。插入的行可以由值表达式或查询结果指定,跟标准的sql语法一致。INSERT INTO table_identifier [ part_spec ] [ column_list ] { value_expr | query }part_spec可选,...
流数据湖平台Apache Paimon(五)集成 Spark 引擎
第4章 集成 Spark 引擎4.1 环境准备Paimon 目前支持 Spark 3.4、3.3、3.2 和 3.1。课程使用的Spark版本是3.3.1。1)上传并解压Spark安装包tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/mv /...

大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
一、概述Hudi(Hadoop Upserts Deletes and Incrementals),简称Hudi,是一个流式数据湖平台,支持对海量数据快速更新,内置表格式,支持事务的存储层、 一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具,它可以以极低的延迟将数据快...

杭州 Meetup| Apache Kyuubi & Celeborn,助力 Spark 拥抱云原生
Apache Spark 作为如今大数据离线计算领域事实标准,被广泛应用。Apache Celeborn (Incubating)是大数据引擎统一中间数据服务,除了支持 Shuffle,未来还会支持 Spilled data,帮助计算节点解除对大容量本地盘的依赖。这是在阿里云上诞生的第一个 Apac...
Apache IoTDB开发系统整合之TsFile-Spark-Connector
TsFile-Spark-Connector用户指南1. TsFile-Spark-Connector简介TsFile-Spark-Connector 实现了 Spark 对 Tsfile 类型的外部数据源的支持。这使用户能够通过Spark读取,写入和查询Tsfile。使用此连接器,您可以将单个 T...

Apache Kyuubi & Celeborn (Incubating) 助力 Spark 拥抱云原生
本文整理自网易数帆软件工程师潘成,在 ASF CommunityOverCode Asia 2023(北京)的分享。本篇内容主要为: Spark 云原生的收益和挑战如何基于 Apache Kyuubi 构建统一 Spark 任务网关如何基于 Apache Celeborn (Incubating) ...

Apache Celeborn 让 Spark 和 Flink 更快更稳更弹性
摘要:本文整理自阿里云/数据湖 Spark 引擎负责人周克勇(一锤)在 Streaming Lakehouse Meetup 的分享。内容主要分为五个部分: Apache Celeborn 的背景Apache Celeborn——快Apache Celeborn——稳Apache Celeborn—...

Apache Doris Spark Load快速体验之Spark部署(1)2
配置初始化#进入spark配置目录 cd /opt/spark3.3.2/conf cp spark-env.sh.template spark-env.sh #新增如下配置 vim spark-env.sh export JAVA_HOME=/usr/local/java/jdk1.8.0_361...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作