图加速数据湖分析-GeaFlow和Apache Hudi集成
表模型现状与问题 关系模型自1970年由埃德加·科德提出来以后被广泛应用于数据库和数仓等数据处理系统的数据建模。关系模型以表作为基本的数据结构来定义数据模型,表为二维数据结构,本身缺乏关系的表达能力,关系的运算通过Join关联运算来处理。表模型简单且易于理解,在关系模型中被广泛使用。随着互联网信息技...
流数据湖平台Apache Paimon(六)集成Spark之DML插入数据
4.4. 插入数据INSERT 语句向表中插入新行。插入的行可以由值表达式或查询结果指定,跟标准的sql语法一致。INSERT INTO table_identifier [ part_spec ] [ column_list ] { value_expr | query }part_spec可选,...

流数据湖平台Apache Paimon(五)集成 Spark 引擎
第4章 集成 Spark 引擎4.1 环境准备Paimon 目前支持 Spark 3.4、3.3、3.2 和 3.1。课程使用的Spark版本是3.3.1。1)上传并解压Spark安装包tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /opt/module/mv /...
流数据湖平台Apache Paimon(四)集成 Hive 引擎
第3章 集成 Hive 引擎前面与Flink集成时,通过使用 paimon Hive Catalog,可以从 Flink 创建、删除、查询和插入到 paimon 表中。这些操作直接影响相应的Hive元存储。以这种方式创建的表也可以直接从 Hive 访问。更进一步的与 Hive 集成,可以使用 Hiv...

流数据湖平台Apache Paimon(二)集成 Flink 引擎
第2章 集成 Flink 引擎Paimon目前支持Flink 1.17, 1.16, 1.15 和 1.14。本课程使用Flink 1.17.0。2.1 环境准备环境准备2.1.1 安装 Flink1)上传并解压Flink安装包tar -zxvf flink-1.17.0-bin-scala_2.1...
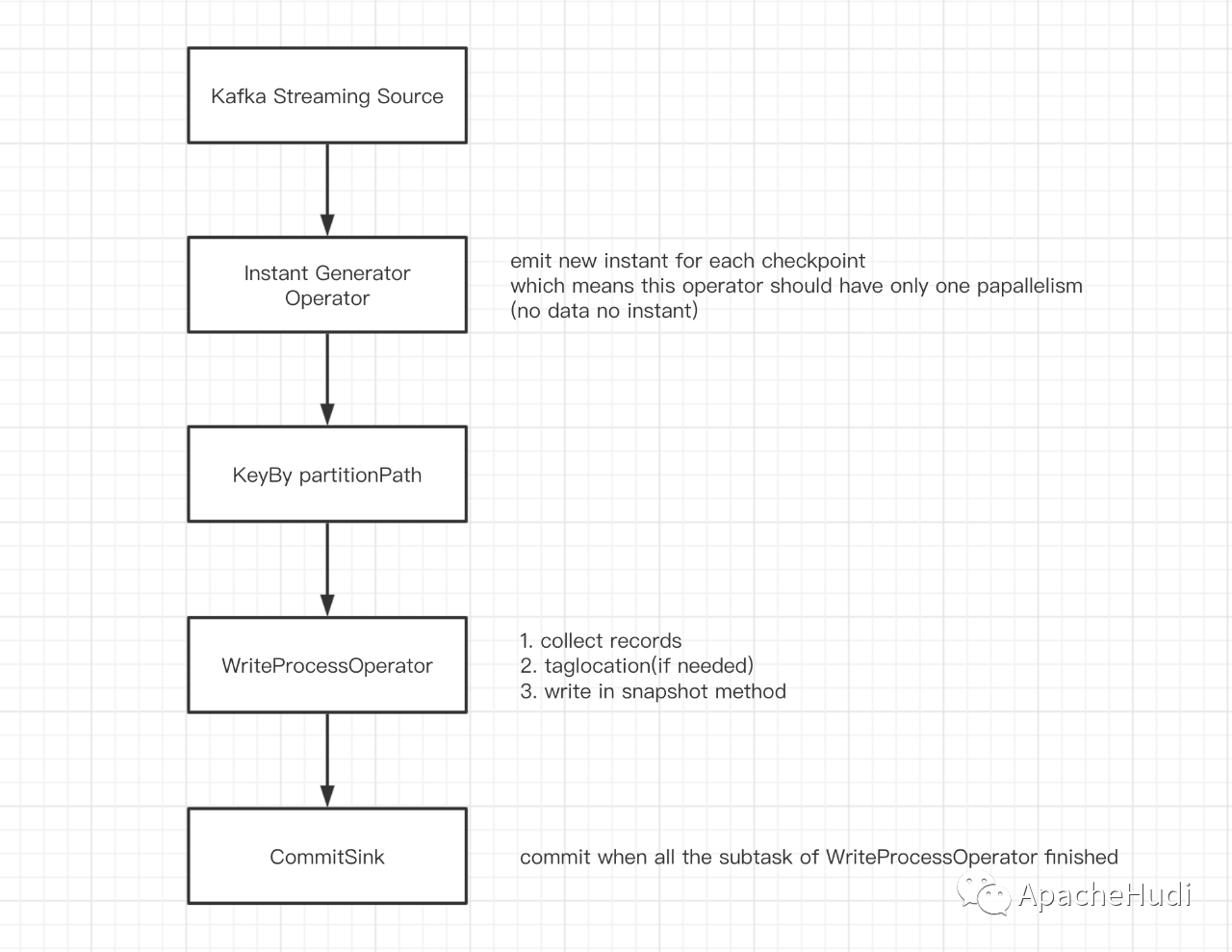
数据湖有新解!Apache Hudi 与 Apache Flink 集成
作者:王祥虎(Apache Hudi 社区) Apache Hudi 是由 Uber 开发并开源的数据湖框架,它于 2019 年 1 月进入 Apache 孵化器孵化,次年 5 月份顺利毕业晋升为 Apache 顶级项目。是当前最为热门的数据湖框架之一。 1. 为何要解耦 Hudi 自诞生至今一直使...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








