阿里云E-MapReduce Trino专属集群外连引擎及权限控制踩坑实践
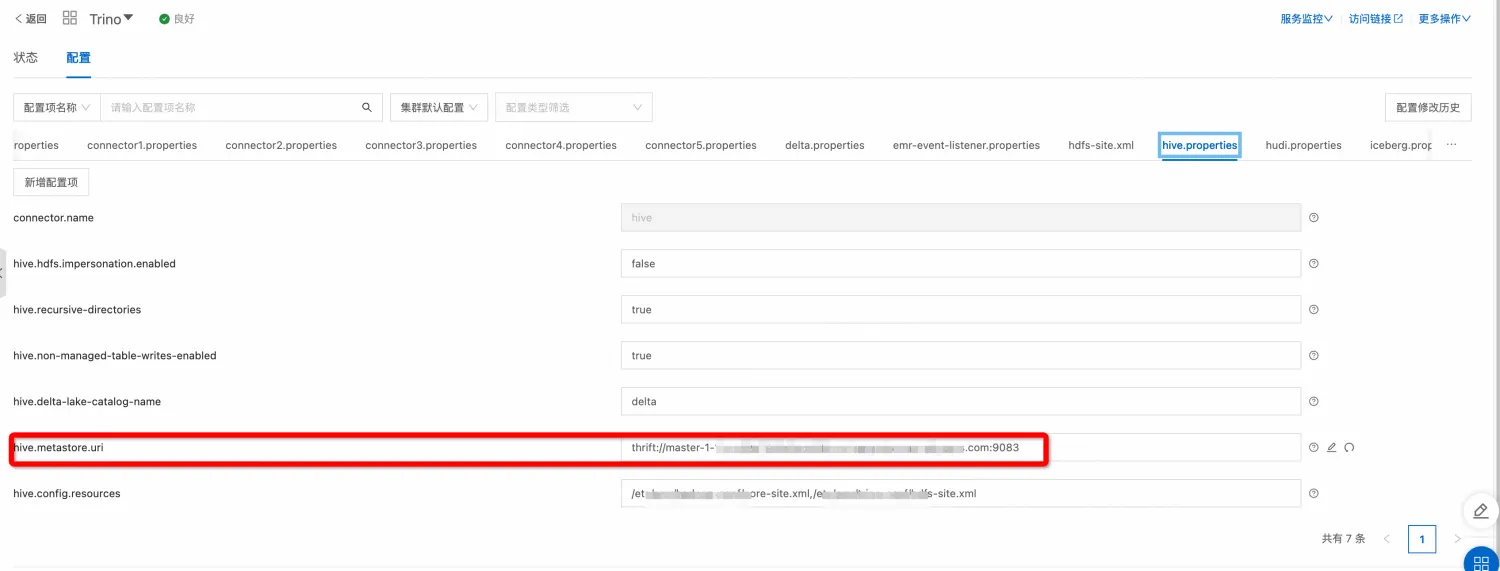
1. 专属Olap集群-Trino/Presto 1.1. 客户需求 EMR-Trino集群,连接Ack集群上的Hive-metastore、Mysql以及ODPS。 其中最为复杂的为自建hive connector的相关配置: 从表类型方面看包含普通hive表以及delta表 从存储方面看包含hd...
[帮助文档] BrokerLoad如何导入,操作,系统配置及实践
Broker Load是一个异步的导入方式,支持的数据源取决于Broker进程支持的数据源。本文为您介绍Broker Load导入的基本原理、基本操作、系统配置以及最佳实践。

阿里云E-MapReduce有大佬有通过jindofs建odps外表连oss的实践分享不?
阿里云E-MapReduce有大佬有通过jindofs建odps外表连oss的实践分享不?
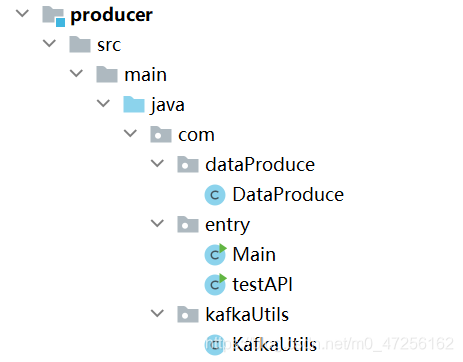
Kafka-HBase-MapReduce-Mysql 连接实践 通话记录
1.项目介绍本项目采用的数据为通话记录数据,例(张三 李四 2021-4-23 12:32:13 2942)意思是张三在2021-4-23 12:32:13这个时间给李四通话,通话时长为2942秒数据来源【程序自己模拟数据的产生,交给Kafka的生产者】Kafka的消费者端接的是HBase数据库Ma...
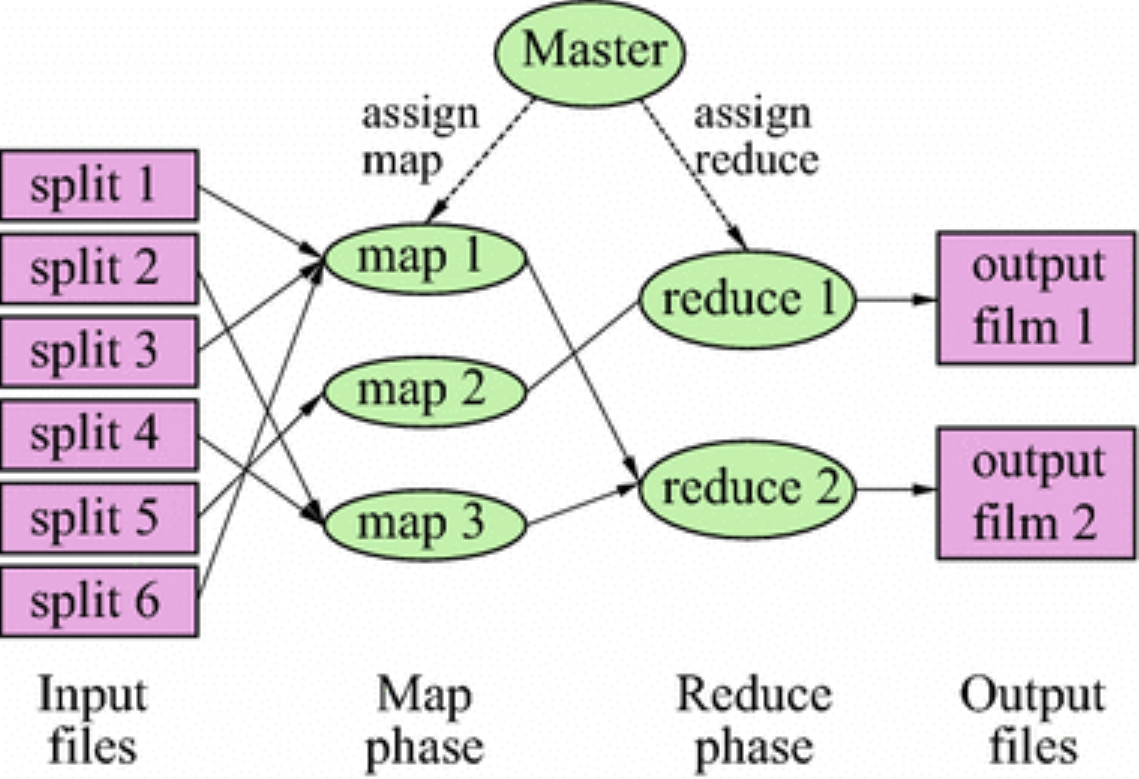
MapReduce 原理与实践
MapReduce 简介MapReduce 核心思想Hadoop MapReduce 是一个编程框架,它可以轻松地编写应用程序,以可靠的、容错的方式处理大量的数据(数千个节点)。正如其名,MapReduce 的工作模式主要分为 Map 阶段和 Reduce 阶段。一个 MapReduce 任务(Jo...

实践Hadoop MapReduce 任务的性能翻倍之路
作者:李万雪, eBay软件开发工程师,2017年毕业于上海交通大学。目前负责日志在大数据平台上的分析和opentracing在ebay日志平台的实现。 原文链接:https://mp.weixin.qq.com/s?__biz=MzA3MDMyNDUzOQ==&mid=2650505625...
[MaxCompute MapReduce实践]通过简单瘦身,解决Dataworks 10M文件限制问题
用户在DataWorks上执行MapReduce作业的时候,文件大于10M的JAR和资源文件不能上传到Dataworks,导致无法使用调度去定期执行MapReduce作业。 解决方案: 第一步:大于10M的resources通过MaxCompute CLI客户端上传, 客户端下载地址:https:/...
hive在E-MapReduce集群的实践(一)hive异常排查入门
hive是hadoop集群最常用的数据分析工具,只要运行sql就可以分析海量数据。初学者在使用hive时,经常会遇到各种问题,不知道该怎么解决。 本文是hive实践系列的第一篇,以E-MapReduce集群环境为例,介绍常见的hive执行异常,定位和解决方法,以及hive日志查看方法。 除作者本人的...
hive在E-MapReduce集群的实践(二)集群hive参数优化
本文介绍一些常见的集群跑hive作业参数优化,可以根据业务需要来使用。 提高hdfs性能 修改hdfs-site,注意重启hdfs服务 dfs.client.read.shortcircuit=true //直读 dfs.client.read.shortcircuit.streams.cache....
阿里云AnalyticDB数据导出到E-MapReduce实践
阿里云的分析型数据库(AnalyticDB)和E-MapReduce(简称EMR)在大数据场景下非常有用,本文将介绍如何尝试打通两个产品,将通过EMR中自带的开源工具Sqoop来完成这个任务。 AnalyticDB数据准备 在DMS For Analytic DB控制台可以新建数据库和表。数据库和表...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce实践相关内容
mapreduce您可能感兴趣
- mapreduce hive
- mapreduce oss
- mapreduce访问
- mapreduce配置
- mapreduce sdk
- mapreduce策略
- mapreduce优化
- mapreduce模型
- mapreduce编程
- mapreduce实战
- mapreduce hadoop
- mapreduce集群
- mapreduce hdfs
- mapreduce spark
- mapreduce maxcompute
- mapreduce程序
- mapreduce yarn
- mapreduce数据
- mapreduce运行
- mapreduce任务
- mapreduce wordcount
- mapreduce map
- mapreduce大数据
- mapreduce作业
- mapreduce案例
- mapreduce入门