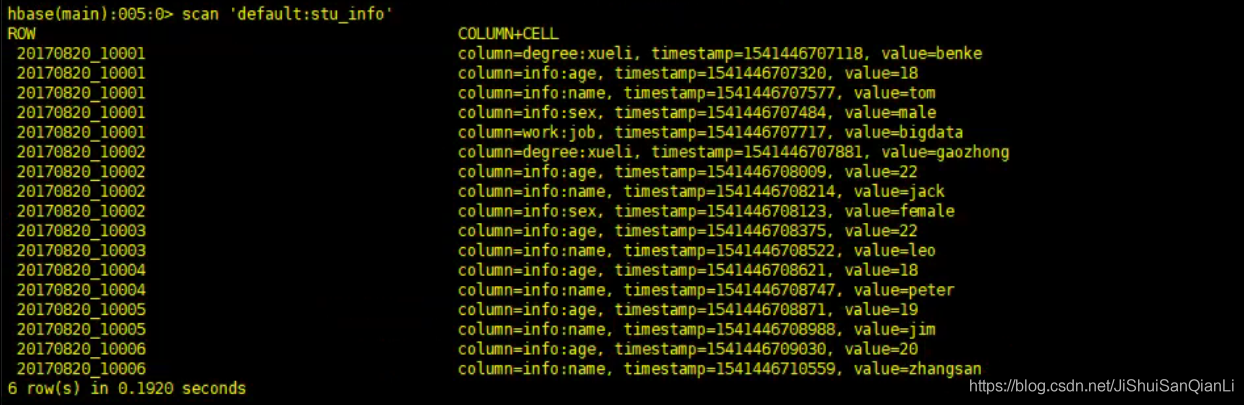
Hbase实践将所有info列簇下的name列导入到另一张表中
将所有info列簇下的name列导入到另一张表中建表:读取的表:create 'stu_info','info','degree','work'写入的表:create 't5',{NAME => 'info'}put 'stu_info&...
[帮助文档] 如何实现日志服务的增量导入
本文主要介绍日志服务(SLS)增量导入的操作过程。

[帮助文档] 在HBase中如何进行RDS增量导入
本文主要介绍在HBase中如何进行RDS增量导入。
[帮助文档] 在HBase中如何进行RDS全量导入
本文主要介绍在HBase中如何进行RDS全量导入。
flinkcdc 同步mysql数据到hbase,flink任务启动,导入全量数据有反压,怎么办?
flinkcdc 同步mysql数据到hbase,flink任务启动,导入全量数据有反压,反压结束以后,新的数据不会写入hbase,看日志无明显错误,怎么办?
[帮助文档] HBase数据如何导入Serverless实例
本文介绍数据如何导入Serverless实例。
hbase要导入一亿行用户表数据,如果用自增主键作为rowkey会出现什么问题,要怎么设计rowke
hbase要导入一亿行用户表数据,如果用自增主键作为rowkey会出现什么问题,要怎么设计rowkey
Hbase自带API的导入和导出方式是什么呢?
Hbase自带API的导入和导出方式是什么呢?
通过Datax将CSV文件导入Hbase,导入之前的CSV文件大小和导入之后的Hadoop分布式文件大小对比引入的思考
由于项目需要做系统之间的离线数据同步,因为实时性要求不高,因此考虑采用了阿里的datax来进行同步。在同步之前,将数据导出未csv文件,因为需要估算将来的hbase运行的hadoop的分布式文件系统需要占用多少磁盘空间,因此想到了需要做几组测试。几个目的:1、估算需要的hadoop的分布式文件系统需...
请教各位大神,hbase2.0 spark批量导入时报这个,有人碰到过么
请教各位大神,hbase2.0 spark批量导入时报这个,有人碰到过么。已经按rowkey排过序了 本问题来自阿里云开发者社区的【11大垂直技术领域开发者社群】。 https://developer.aliyun.com/article/706511 点击链接欢迎加入感兴趣的技术领域群
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。






云数据库HBase版您可能感兴趣
- 云数据库HBase版表
- 云数据库HBase版dataworks
- 云数据库HBase版方法
- 云数据库HBase版安装
- 云数据库HBase版linux
- 云数据库HBase版教程
- 云数据库HBase版集群部署
- 云数据库HBase版配置
- 云数据库HBase版分布式
- 云数据库HBase版hdfs
- 云数据库HBase版数据
- 云数据库HBase版shell
- 云数据库HBase版hadoop
- 云数据库HBase版集群
- 云数据库HBase版hive
- 云数据库HBase版flink
- 云数据库HBase版报错
- 云数据库HBase版操作
- 云数据库HBase版数据库
- 云数据库HBase版spark
- 云数据库HBase版设计
- 云数据库HBase版存储
- 云数据库HBase版大数据
- 云数据库HBase版phoenix
- 云数据库HBase版查询
- 云数据库HBase版学习笔记
- 云数据库HBase版技术