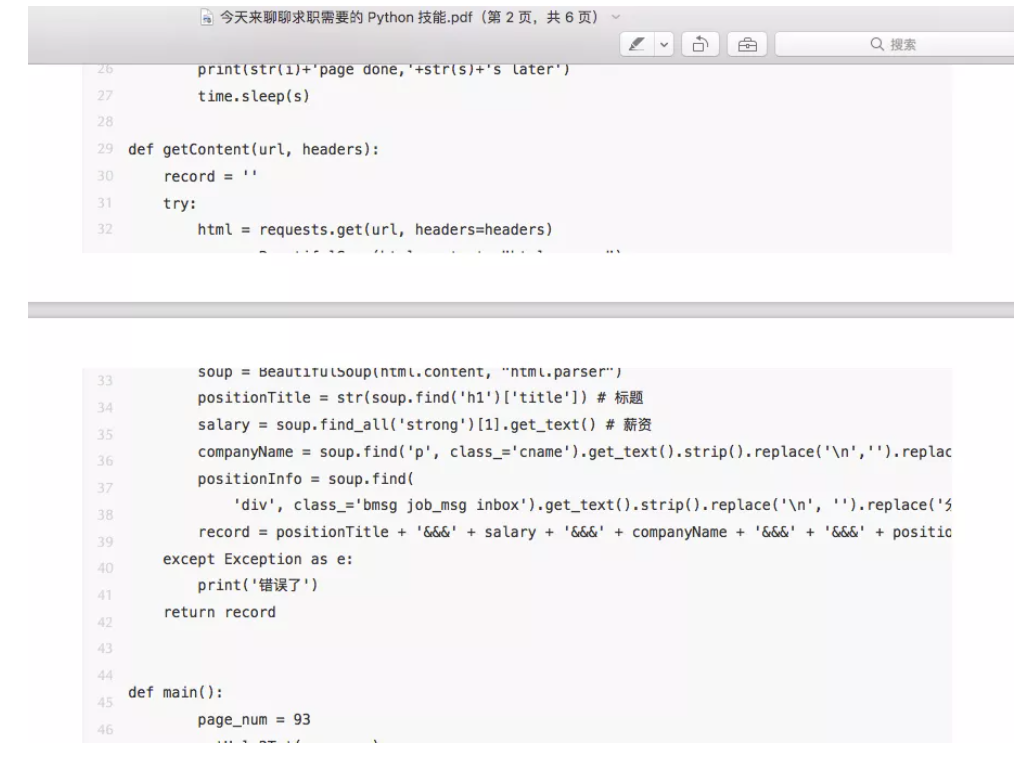
用 Python 抓取公号文章保存成 HTML
上次为大家介绍了如果用 Python 抓取公号文章并保存成 PDF 文件存储到本地。但用这种方式下载的 PDF 只有文字没有图片,所以只适用于没有图片或图片不重要的公众号,那如果我想要图片和文字下载下来怎么办?今天就给大家介绍另一种方案——HTML。需解决的问题其实我们要解决的有两个问题:公众号里的...
怎么写抓取的 html 特征节点:报错
@黄亿华 你好,想跟你请教个问题: page.putField("intro",page.getHtml().xpath("//div[@class='left_648 top_border']/div[... 要得到图中的文字, 上面这个表达式 是要怎么写 ?

Python3抓取javascript生成的html网页
用urllib等抓取网页,只能读取网页的静态源文件,而抓不到由javascript生成的内容。 究其原因,是因为urllib是瞬时抓取,它不会等javascript的加载延迟,所以页面中由javascript生成的内容,urllib读取不到。 那由javascript生成的内容就真的没...
(转载)Python写爬虫--抓取网页并解析HTML
CUHK上学期有门课叫做Semantic Web,课程project是要搜集整个系里面的教授信息,输入到一个系统里,能够完成诸如“如果选了A教授的课,因时间冲突,B教授的哪些课不能选”、 “和A教授实验室相邻的实验室都是哪些教授的”这一类的查询。这就是所谓的“语义网”了啊。。。然而最坑爹的是,所有这...
iOS抓取HTML ,CSS XPath解析数据
以前我们获取数据的方式都是使用 AFN 来 Get JSON 数据,比如 点我查看 JSON 数据.http://news-at.zhihu.com/api/4/news/latest 但例如下面的百度贴吧,和豆瓣读书等网站...并不提供我们获取数据的 API 百度贴吧: 百...
JS跨域抓取HTML页面并解析
RT,想通过JS抓取远端的HTML页面并解析页面(能分别解析tag最好,不能的话正则吧)获取内容不是node.js就是本地的javascript(或者jquery)想知道这种想法能实现么?
JS跨域抓取HTML页面并解析
RT,想通过JS抓取远端的HTML页面并解析页面(能分别解析tag最好,不能的话正则吧)获取内容 不是node.js就是本地的javascript(或者jquery)想知道这种想法能实现么?
正则表达式抓取一个HTML里面的INPUT标签
# 收银台 ## 用正则抓取,ID和name是固定的就是value会变
Jsoup如何抓取需要登录才能显示的html页面?
Connection.Response res = Jsoup.connect("http://www.example.com/login.php") .data("username", "myUsername", "password", "myPassword") .method(Method.P...
通过shell抓取html数据
最近看一些网站的时候,发现有些数据很有意思,想把数据截取出来,但是想把数据抽取出来很是困难。因为如下的小方框的数字都是上下两行排列,想要把数据抽取到一行是很难实现的。斯达 2:3 斯特罗姆 23:57 欧 亚 析 0-...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








