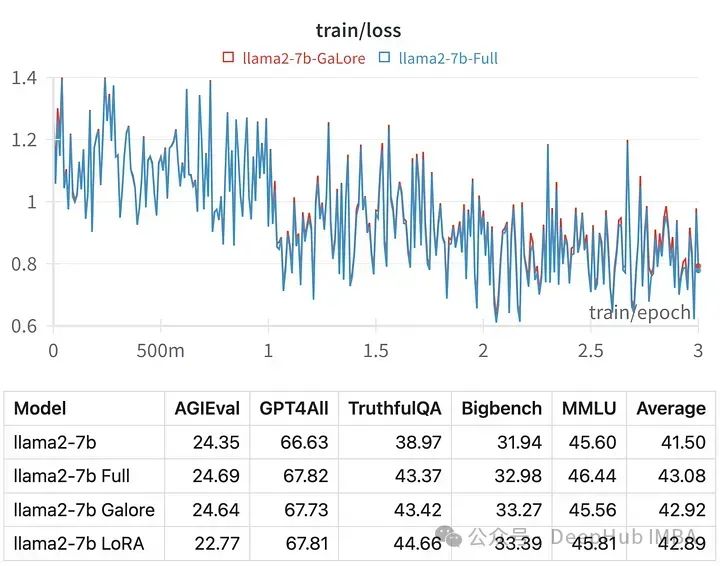
使用GaLore在本地GPU进行高效的LLM调优
训练大型语言模型(llm),即使是那些“只有”70亿个参数的模型,也是一项计算密集型的任务。这种水平的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(LoRA)等参数高效方法,可以在消费级gpu上对大量模型进行微调。 GaLore是一种新的方法,它不是通过直接减少参...
LLM大语言模型有个100并发的34b模型的推理需求,不知道需要多大的GPU?
LLM大语言模型有个100并发的34b模型的推理需求,不知道需要多大的GPU?First token需要在2s内,部署的话应该是使用vLLM加速

使用Accelerate库在多GPU上进行LLM推理
所以本文将在多个gpu上并行执行推理,主要包括:Accelerate库介绍,简单的方法与工作代码示例和使用多个gpu的性能基准测试。 本文将使用多个3090将llama2-7b的推理扩展在多个GPU上 基本示例 我们首先介绍一个简单的示例来演示使用Accelerate进行多gpu“消息传递”。 fr...
[帮助文档] 使用DeepGPU-LLM实现大语言模型在GPU上的推理优化
在处理大语言模型任务中,您可以根据实际业务部署情况,选择在不同环境(例如GPU云服务器环境或Docker环境)下安装推理引擎DeepGPU-LLM,然后通过使用DeepGPU-LLM工具实现大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)在GPU上...
[帮助文档] 大语言模型( LLM)推理引擎DeepGPU-LLM
DeepGPU-LLM是阿里云研发的基于GPU云服务器的大语言模型(Large Language Model,LLM)推理引擎,在处理大语言模型任务中,该推理引擎可以为您提供高性能的大模型推理服务。
ModelScope中求教一下,我GPU显存不够,怎么强制用CPU运行魔搭LLM模型呀?
ModelScope中求教一下,我GPU显存不够,怎么强制用CPU运行魔搭LLM模型呀
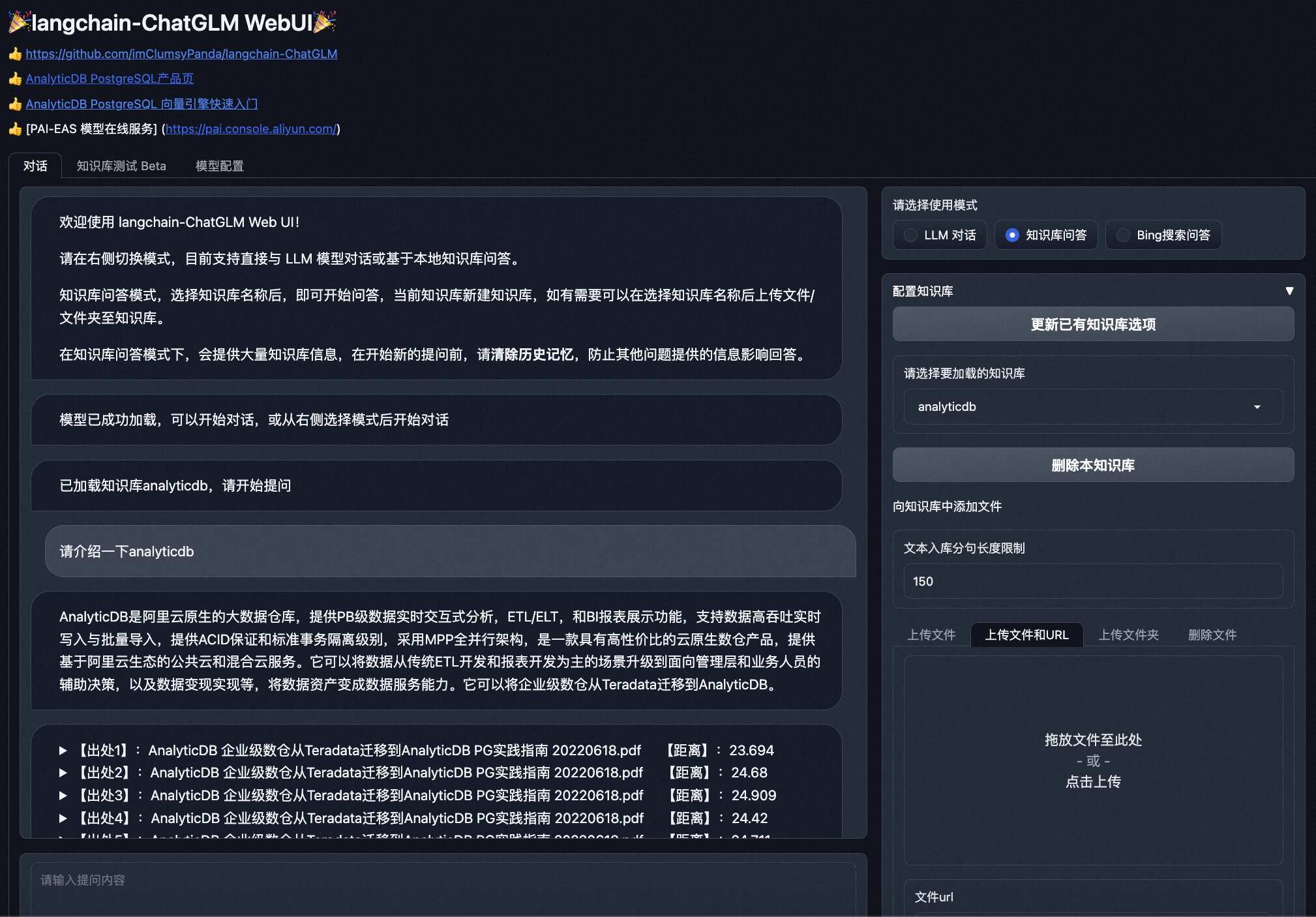
规模化落地AIGC应用,支持多个大语言模型(LLM)切换及GPU规划化管理(PAI-EAS + ADB-PG)
背景随着年初的ChatGPT引爆大语言模型市场, LLM的集中爆发,大部分企业已经完成了AIGC产品的调研,并进入第二阶段, 即寻求大规模落地的AIGC产品解决方案。当前企业在AIGC场景落地中,以下问题尤为突出: 多模型选择: 随着大模型的百花齐放, 不同的模型在各自的领域有不同的优...
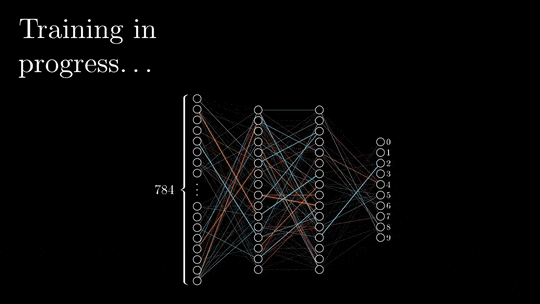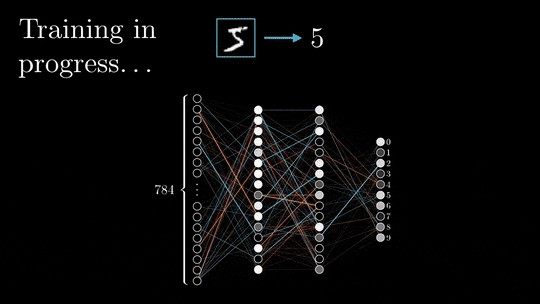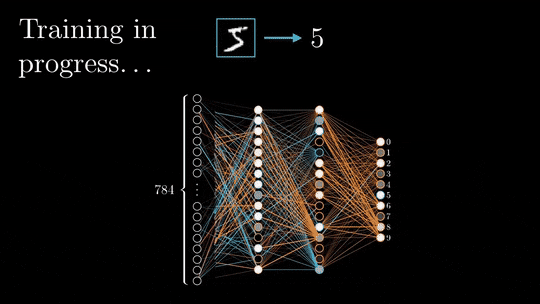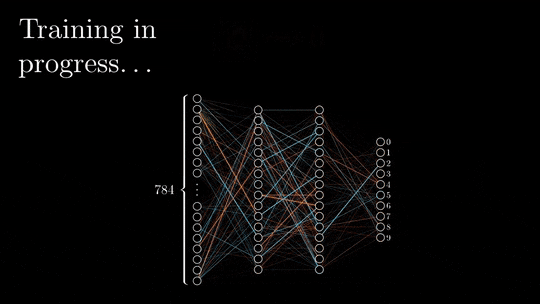
在消费级GPU调试LLM的三种方法:梯度检查点,LoRA和量化
梯度检查点 梯度检查点是一种在神经网络训练过程中使动态计算只存储最小层数的技术。 为了理解这个过程,我们需要了解反向传播是如何执行的,以及在整个过程中层是如何存储在GPU内存中的。 1、前向和后向传播的基本原理 前向传播和后向传播是深度神经网络训练的两个阶段。 在前向传递过程中,输入被矢量化(将图像...

小羊驼背后的英雄,伯克利开源LLM推理与服务库:GPU减半、吞吐数十倍猛增
大模型时代,各种优化方案被提出,这次吞吐量、内存占用大等问题被拿下了。随着大语言模型(LLM)的不断发展,这些模型在很大程度上改变了人类使用 AI 的方式。然而,实际上为这些模型提供服务仍然存在挑战,即使在昂贵的硬件上也可能慢得惊人。现在这种限制正在被打破。最近,来自加州大学伯克利分校...
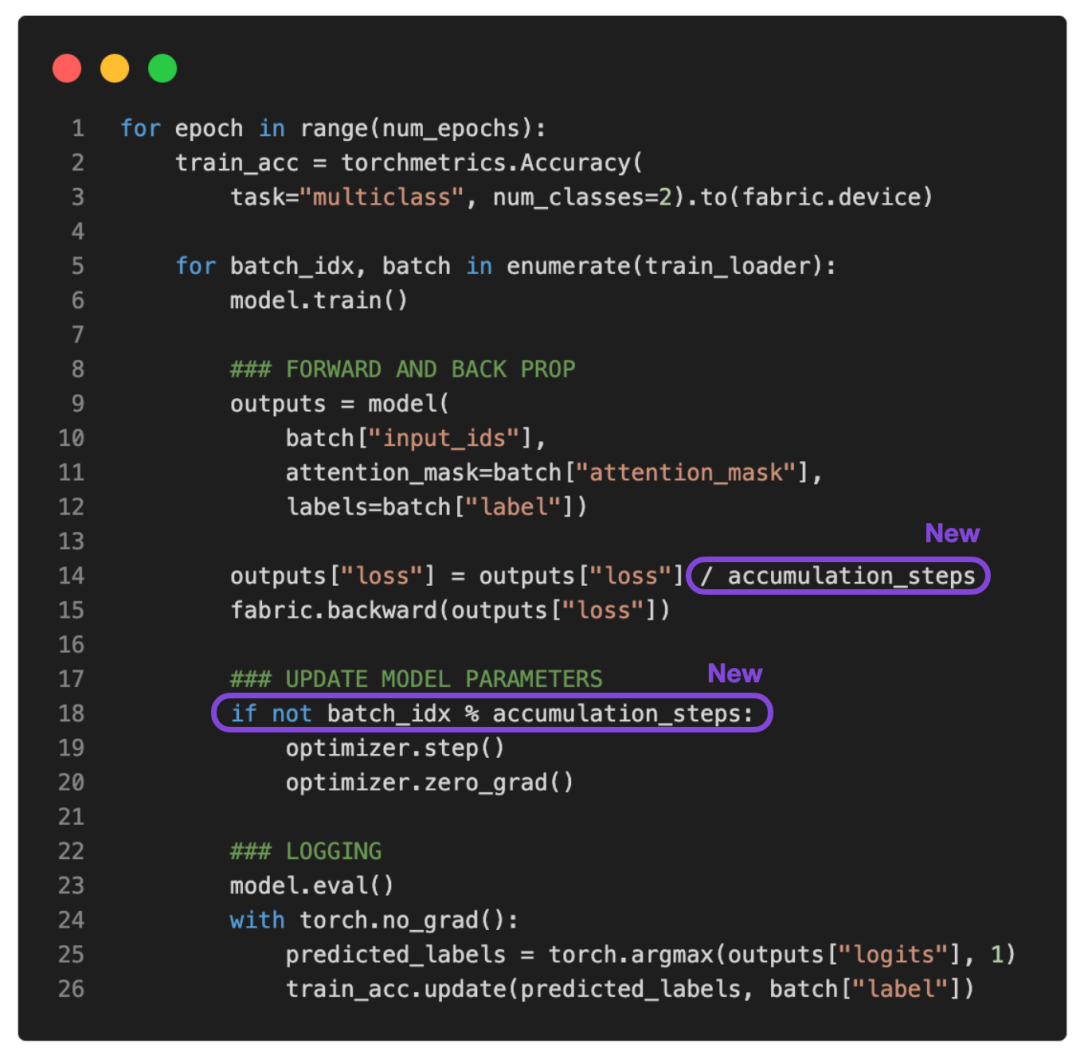
绕开算力限制,如何用单GPU微调 LLM?这是一份「梯度累积」算法教程(2)
由于没有多的 GPU 可用于张量分片(tensor sharding),又能做些什么来训练具有更大批大小(batch size)的模型呢?其中一种解决方法就是梯度累积,可以通过它来修改前面提到的训练循环。什么是梯度积累?梯度累积是一种在训练期间虚拟增加批大小(batch ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








