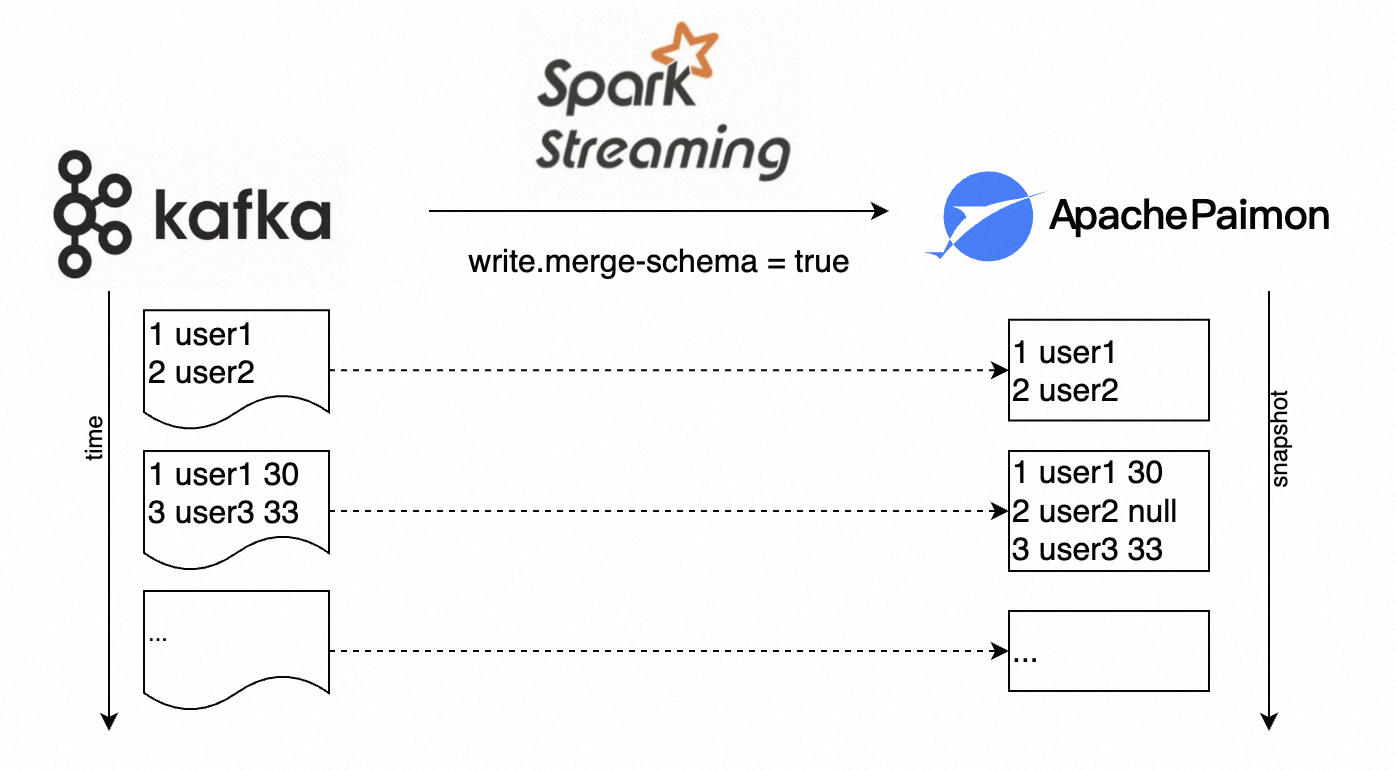
Paimon与Spark的集成(一)
PaimonApache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 ApacheFlink / Spark / Trino 等诸多业界主流计算引擎进行对接,共...
[帮助文档] 如何将Spark集成到Ranger并配置
本文介绍了Spark如何开启Ranger权限控制,以及Ranger Spark权限配置说明。

大数据Spark Structured Streaming集成 Kafka
1 Kafka 数据消费Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。StructuredStreaming很好的集成Kafka,可以从Kafka拉取消息,然后就可以把流数据看...
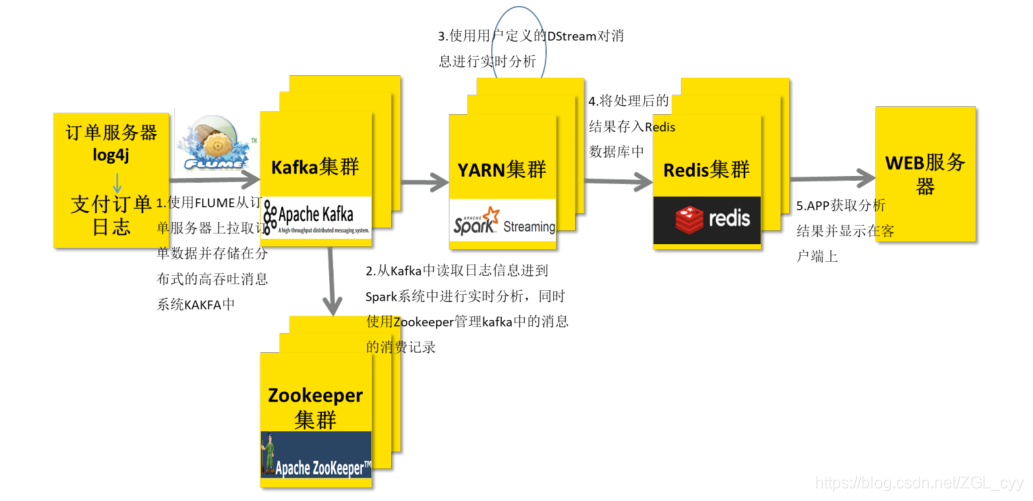
大数据Spark Streaming集成Kafka
1 整合Kafka 0.8.2在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:技术栈: Flume/SDK/Kafka Producer API -> KafKa —> SparkS...
[帮助文档] 如何通过SparkSQL对FlinkTableStore进行读写操作
E-MapReduce的Flink Table Store服务支持通过Spark SQL对Flink Table Store进行读写操作。本文通过示例为您介绍如何通过Spark SQL对Flink Table Store进行读写操作。
[帮助文档] 如何通过SparkSQL对Hudi进行读写操作
E-MapReduce的Hudi 0.8.0版本支持Spark SQL对Hudi进行读写操作,可以极大的简化Hudi的使用成本。本文为您介绍如何通过Spark SQL对Hudi进行读写操作。
E-MapReduce如何配置Spark集成Ranger
E-MapReduce如何配置Spark集成Ranger
E-MapReduce如何实现Hudi与Spark SQL集成
E-MapReduce如何实现Hudi与Spark SQL集成
[帮助文档] 时空几何之Spark集成分析的概述
用户可以通过DLA Ganos实现Spark加载HBase中的时空数据并进行大规模时空分析操作。DLA Ganos是基于云原生数据湖分析(Data Lake Analytics,DLA)系统设计开发的,面向时空大数据存储与计算的数据引擎产品。基于DLA无服务器化(Serverless)数据湖分析服务...

【Spark Streaming】(五)Spark Streaming 与 Kafka 集成实战!
文章目录一、前言二、项目准备2.1 添加Kafka的pom依赖2.2 启动zookeeper集群2.3 启动kafka集群2.4 创建topic2.5 向topic中生产数据三、KafkaUtils.createDstream3.1 原理3.2 实战四、KafkaUtils.createDirect...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








