[帮助文档] 多轮query改写
1. 参数1.1 入参一级参数参数类型是否必传说明algorithmstring是标识符versionstring否版本,默认defaultinputmap是输入参数parametersmap否配置参数debugboolean否调试模式...
[帮助文档] 数据处理状态查询
用于查询源数据的处理进度,为了保证查询服务的稳定性,该方法存在分钟级的缓存信息,对于实时性要求高的场景支持配置秒级的缓存,单次查询支持最大文档数为50。

[帮助文档] 搜索判定
1. 参数1.1 入参一级参数参数类型是否必传说明algorithmstring是标识符versionstring否版本,默认defaultinputmap是输入参数parametersmap否配置参数debugboolean否调试模式...
[帮助文档] 服务数据导入
1. 描述当前仅支持实时链路服务,如出现索引构建版本不支持异常请联系管理员处理。查询导入进度请使用PostMSDataProcessingCount接口2. 参数2.1. 入参参数类型是否必传说明ServiceIdLong是服务idDataTypeString是数据类型;document:文档,完整...
[帮助文档] 服务数据删除
1.1. 参数1.1.1. 入参参数类型是否必传说明serviceIdLong是服务ididsList是待删除数据的主键id{ "serviceId": 1, "ids": [1] }1.1.2. 出参参数名称参数类型参数描述codeInteger错误码successBoolean是否成功r...
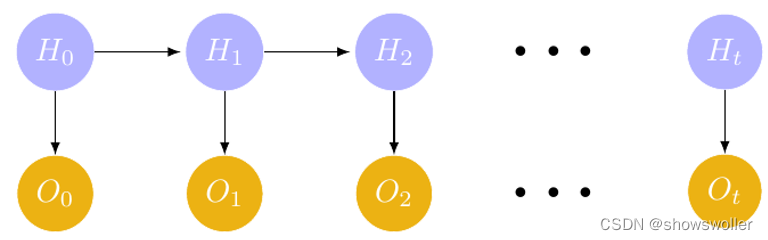
【Python自然语言处理】隐马尔可夫模型中维特比(Viterbi)算法解决商务选择问题实战(附源码 超详细必看)
需要源码请点赞关注收藏后评论区留言私信~~~一、统计分词统计分词基本逻辑是把每个词语看做由单字组成,利用统计学原理计算连接字在不同文本中出现的次数,以此判断相连字属于特定词语的概率。二、隐马尔可夫模型当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态,那么此随...
![深度学习应用篇-自然语言处理[10]:N-Gram、SimCSE介绍,更多技术:数据增强、智能标注、多分类算法、文本信息抽取、多模态信息抽取、模型压缩算法等](https://ucc.alicdn.com/fnj5anauszhew_20230612_ae15e835557746388e1276a251ca74b6.png)
深度学习应用篇-自然语言处理[10]:N-Gram、SimCSE介绍,更多技术:数据增强、智能标注、多分类算法、文本信息抽取、多模态信息抽取、模型压缩算法等
深度学习应用篇-自然语言处理[10]:N-Gram、SimCSE介绍,更多技术:数据增强、智能标注、多分类算法、文本信息抽取、多模态信息抽取、模型压缩算法等 1.N-Gram N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的...
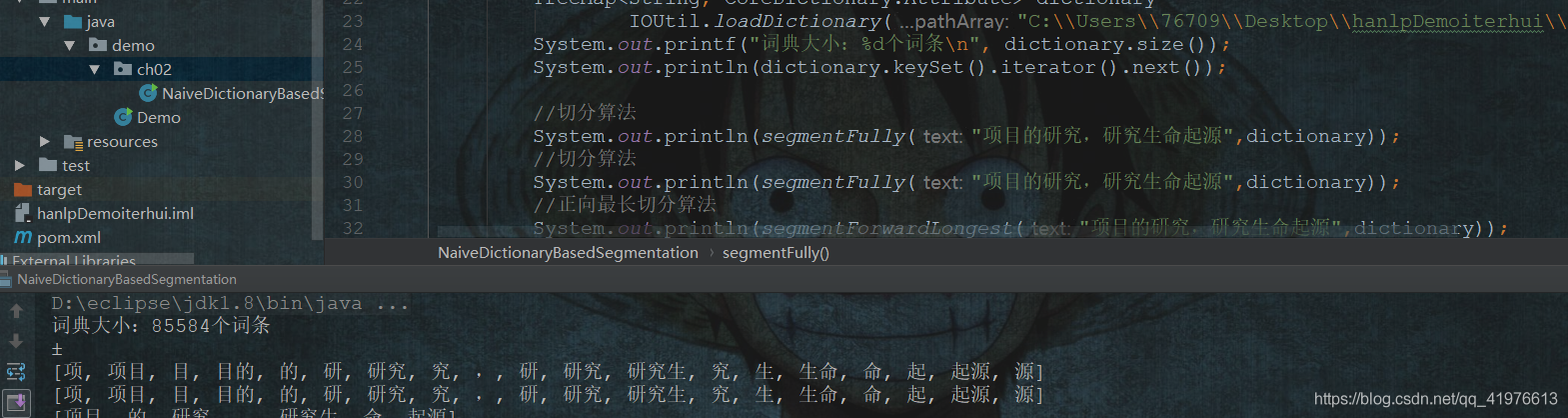
自然语言处理hanlp------5切分算法
一、完全切分式的中文分词算法严格意义上,并不是真正的分词算法,极不准确案例代码如下:/** * 完全切分式的中文分词算法 * * @param text 待分词的文本 * @param dictionary 词典 * @return 单词列表 */ p...

预约直播 | 基于预训练模型的自然语言处理及EasyNLP算法框架
一、分享议题:基于预训练模型的自然语言处理及EasyNLP算法框架二、直播时间:2022年08月24日(周三)18:00-18:30 三、 议题介绍:此次分享将深入介绍预训练语言模型的研究进展以及各种下游自然语言理解的应用;为了解决大模型落地难问题,重点展示多种知识蒸馏、...
自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下! TextRank是在Google的PageRank算法启发下,针对文本里的句子设计的权重算法,目标是自动摘要。它利用投票的...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









