大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和H...

【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~线性回归过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10通...

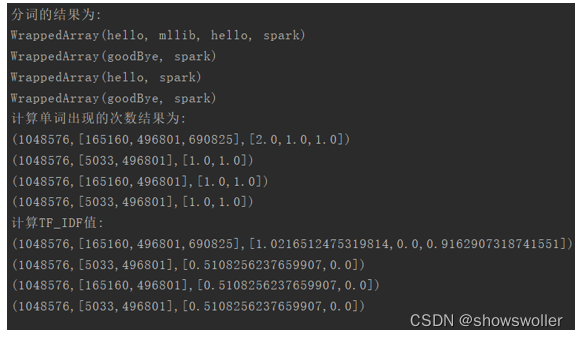
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...
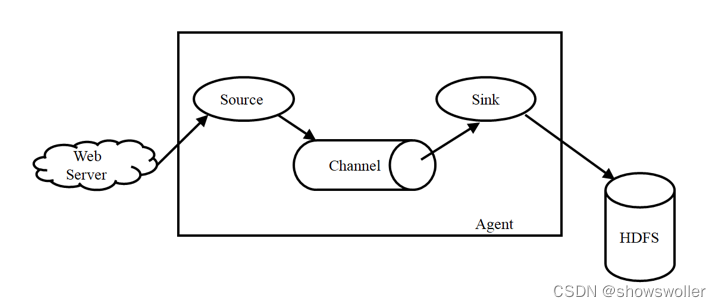
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:...
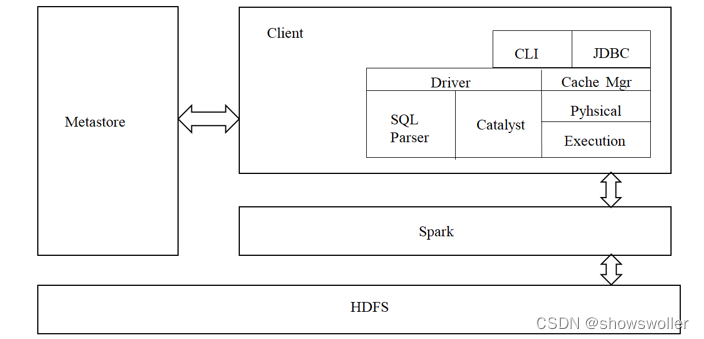
【大数据技术Hadoop+Spark】Spark SQL、DataFrame、Dataset的讲解及操作演示(图文解释)
一、Spark SQL简介park SQL是spark的一个模块,主要用于进行结构化数据的SQL查询引擎,开发人员能够通过使用SQL语句,实现对结构化数据的处理,开发人员可以不了解Scala语言和Spark常用API,通过spark SQL,可以使用Spark框架提供的强大的数据分析能力。spark...
【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建R...
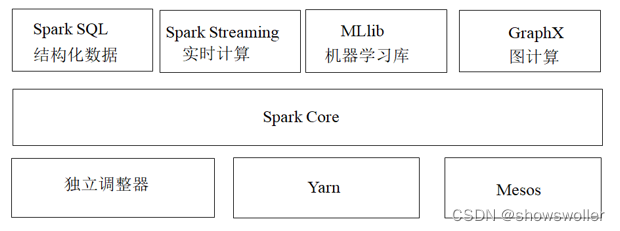
【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心...
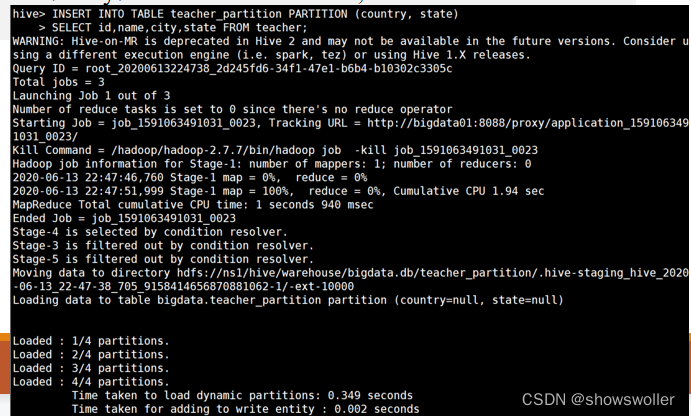
【大数据技术Hadoop+Spark】Hive基础SQL语法DDL、DML、DQL讲解及演示(附SQL语句)
Hive基础SQL语法1:DDL操作DDL是数据定义语言,与关系数据库操作相似,创建数据库CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name显示数据库SHOW databases;查看数据库详情DESC DATABASE|SCHEMA datab...
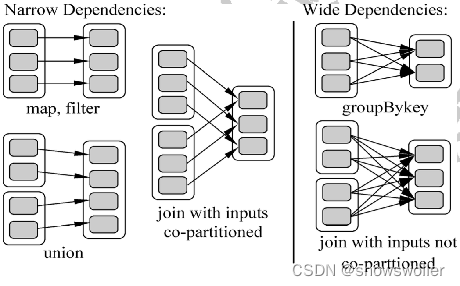
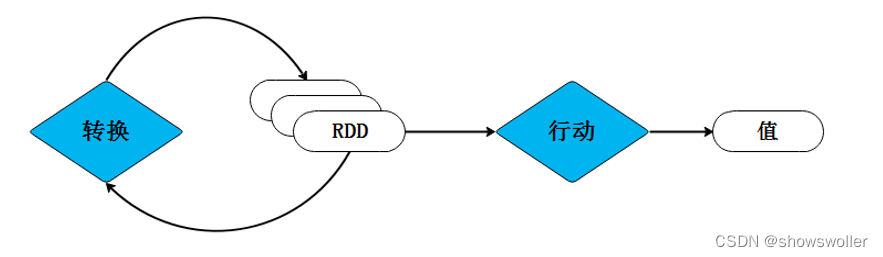
【云计算与大数据技术】Spark的解析(图文解释 超详细必看)
一、Spark RDDSpark是一个高性能的内存分布式计算框架,具备可扩展性,任务容错等特性,每个Spark应用都是由一个driver program 构成,该程序运行用户的 main函数 。Spark提供的一个主要抽象就是 RDD(Resilient Distributed Datasets),...

大数据技术解析:Hadoop、Spark、Flink和数据湖的对比
随着数字化时代的到来,数据已经成为企业和组织的重要资产之一。为了更好地处理、分析和挖掘海量数据,大数据技术逐渐崭露头角。在本文中,我们将深入探讨大数据处理领域中的一些关键技术,包括 Hadoop、Spark、Flink 和数据湖,分析它们的优势、劣势以及适用场景。 Hadoop Hadoop 是一个...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








云原生大数据计算服务 MaxCompute技术相关内容
- 技术云原生大数据计算服务 MaxCompute
- 数据库技术云原生大数据计算服务 MaxCompute应用
- 云原生技术云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute技术工具
- 云原生大数据计算服务 MaxCompute技术apache
- 数仓云原生大数据计算服务 MaxCompute技术dolphinscheduler
- 云原生大数据计算服务 MaxCompute技术概述
- 云原生大数据计算服务 MaxCompute技术引擎
- 云原生大数据计算服务 MaxCompute技术运行原理
- 云原生大数据计算服务 MaxCompute技术原理
- 云原生大数据计算服务 MaxCompute工程师数据可视化技术
- 云原生大数据计算服务 MaxCompute工程师技术
- 物联网云原生大数据计算服务 MaxCompute技术
- 云计算云原生大数据计算服务 MaxCompute技术
- 系统云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术数据采集
- 云原生大数据计算服务 MaxCompute技术机器学习
- 云原生大数据计算服务 MaxCompute技术方法
- 云原生大数据计算服务 MaxCompute技术实战源码
- 云原生大数据计算服务 MaxCompute技术数据类型
- 云原生大数据计算服务 MaxCompute技术安装
- 云原生大数据计算服务 MaxCompute技术dstream
- 云原生大数据计算服务 MaxCompute技术读写
- 云原生大数据计算服务 MaxCompute技术优缺点
- 云原生大数据计算服务 MaxCompute技术调度模型
- 云计算云原生大数据计算服务 MaxCompute技术模型
- 云计算云原生大数据计算服务 MaxCompute技术集群
- 云原生大数据计算服务 MaxCompute技术文件
- 云原生大数据计算服务 MaxCompute技术虚拟化
- 云原生大数据计算服务 MaxCompute技术实验
- 云原生大数据计算服务 MaxCompute技术实验命令
- 云原生大数据计算服务 MaxCompute技术在线教育
- 云原生大数据计算服务 MaxCompute技术项目
- 云原生大数据计算服务 MaxCompute技术sqoop
- 产品云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术公开课
- 技术公开课云原生大数据计算服务 MaxCompute
- 聚星客户运营云原生大数据计算服务 MaxCompute算法技术
- 云原生大数据计算服务 MaxCompute技术学习笔记
- 阿里巴巴云原生大数据计算服务 MaxCompute智能技术
- 云原生大数据计算服务 MaxCompute技术框架
- 问答云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术工程师
- 云原生大数据计算服务 MaxCompute入门技术
- 云原生大数据计算服务 MaxCompute入门实战技术
- 阿里云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute产品技术特性
- 阿里技术云原生大数据计算服务 MaxCompute
云原生大数据计算服务 MaxCompute更多技术相关
- 技术云原生大数据计算服务 MaxCompute公开课
- 云原生大数据计算服务 MaxCompute大数据处理编程实践技术简介
- 云原生大数据计算服务 MaxCompute技术专业
- 云原生大数据计算服务 MaxCompute技术共享
- 云原生大数据计算服务 MaxCompute系统技术
- 云原生大数据计算服务 MaxCompute存储技术
- spark云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute技术运营
- kafka云原生大数据计算服务 MaxCompute系统技术重构
- 云原生大数据计算服务 MaxCompute技术研究院
- 云原生大数据计算服务 MaxCompute技术pdf
- 云原生大数据计算服务 MaxCompute技术技术公开课
- 云原生大数据计算服务 MaxCompute智能技术
- 云原生大数据计算服务 MaxCompute技术阿里
- 云原生大数据计算服务 MaxCompute方法技术
- 智能技术云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute技术接轨商业
- 云原生大数据计算服务 MaxCompute技术信息
- 聚星运营云原生大数据计算服务 MaxCompute技术
- teradata革新云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute计算技术
- 云原生大数据计算服务 MaxCompute技术背后
- 技术阻碍云原生大数据计算服务 MaxCompute步伐
- 云原生大数据计算服务 MaxCompute数据计算技术
- 技术公开课云原生大数据计算服务 MaxCompute实战
- 云原生大数据计算服务 MaxCompute平台技术
- 云原生云原生大数据计算服务 MaxCompute技术
- cutting云原生大数据计算服务 MaxCompute技术
- 技术梦想旅行云原生大数据计算服务 MaxCompute旅游
- 技术云计算云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute技术教育
- facebook云原生大数据计算服务 MaxCompute技术
- 全域云原生大数据计算服务 MaxCompute技术
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute数据同步
- 云原生大数据计算服务 MaxCompute配置
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute表数据
- 云原生大数据计算服务 MaxCompute实时同步
- 云原生大数据计算服务 MaxCompute单表
- 云原生大数据计算服务 MaxCompute方案
- 云原生大数据计算服务 MaxCompute订阅
- 云原生大数据计算服务 MaxCompute mysql
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目