Transformer 落地出现 | Next-ViT实现工业TensorRT实时落地,超越ResNet、CSWin(二)
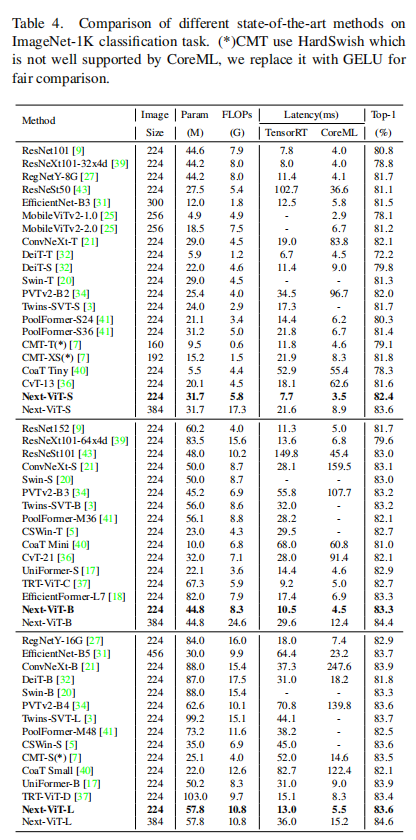
3实验3.1 图像分类3.2 目标检测3.3 语义分割4参考[1].Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios5推荐阅读超越 ConvN...
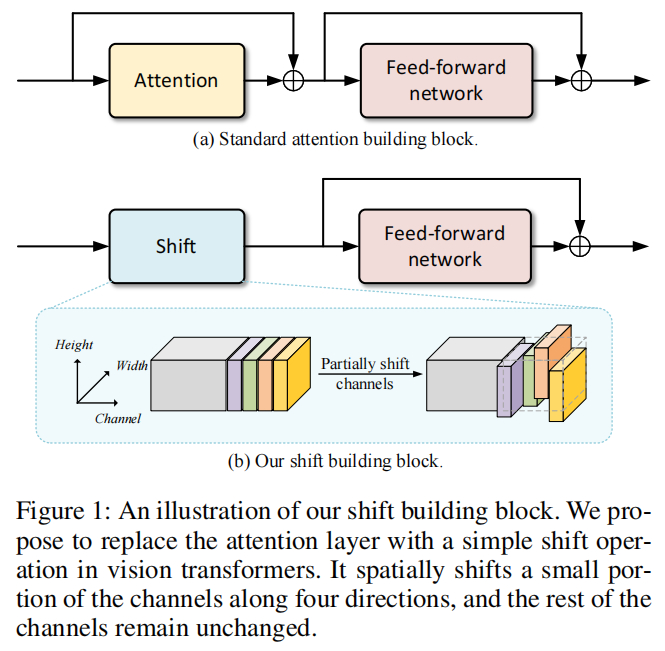
ShiftViT用Swin Transformer的精度跑赢ResNet的速度,论述ViT的成功不在注意力!(一)
1简介Backbone的设计在计算机视觉中起着至关重要的作用。自从AlexNet的革命性进步以来,卷积神经网络(CNNs)已经主导了这个邻域近10年。然而,最近的ViTs已经显示出了挑战这个宝座的潜力。ViT的优势首先在图像分类任务中得到了证明,在该任务中,ViT的Backbone显著优于CNN的B...
Transformer | 详细解读Transformer怎样从零训练并超越ResNet?(二)
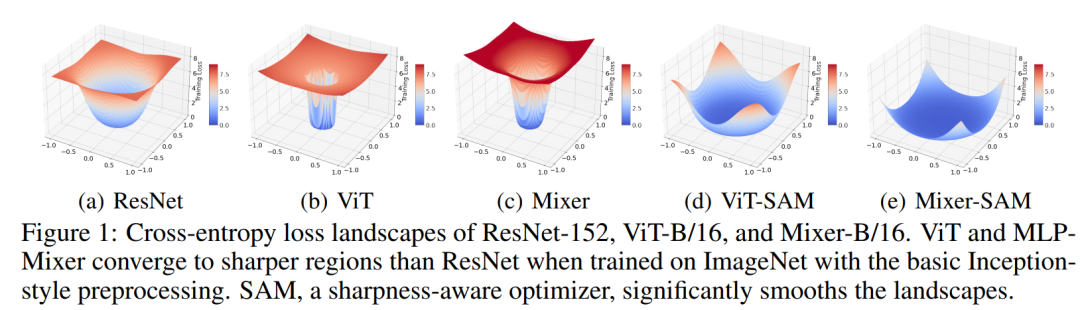
4.3 无需预训练或强大的数据增强ViTs优于ResNets模型体系结构的性能通常与训练策略合并,其中数据增强起着关键作用。然而,数据增广的设计需要大量的领域专业知识,而且可能无法在图像和视频之间进行转换。由于有了锐度感知优化器SAM,可以删除高级的数据增强,并专注于体系结构本身(使用基本的Ince...
Transformer | 详细解读Transformer怎样从零训练并超越ResNet?(一)
1简介Vision Transformers(ViTs)和MLPs标志着在用通用神经架构替换手动特征或归纳偏置方面的进一步努力。现有工作通过大量数据为模型赋能,例如大规模预训练和/或重复的强数据增广,并且还报告了与优化相关的问题(例如,对初始化和学习率的敏感性)。因此,本文从损失几何的角度研究了Vi...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。