【Python 机器学习专栏】随机森林算法的性能与调优
在机器学习领域,随机森林算法是一种强大而灵活的方法。它以其出色的性能和广泛的应用而备受关注。本文将深入探讨随机森林算法的性能特点以及如何对其进行调优。 一、随机森林算法的基本原理 随机森林是一种集成学习方法,它通过构建多个决策树并将它们组合在一起形成一个森林。每个决策树都是基于随机选择的样本和特征进...
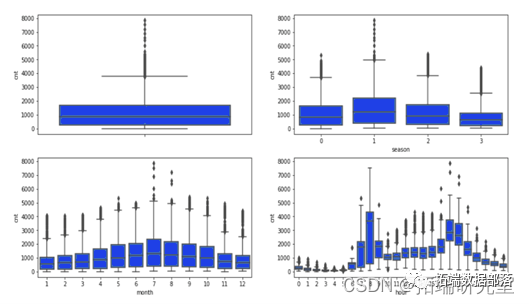
共享单车需求量数据用CART决策树、随机森林以及XGBOOST算法登记分类及影响因素分析
全文链接:http://tecdat.cn/?p=28519 作者:Yiyi Hu 近年来,共享经济成为社会服务业内的一股重要力量。作为共享经济的一个代表性行业,共享单车快速发展,成为继地铁、公交之后的第三大公共出行方式。 但与此同时,它也面临着市场需求不平衡、车辆乱停乱放、车辆检修调度等问题。本项...


数据分享|R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
原文链接:http://tecdat.cn/?p=23061 数据集信息: 这个数据集(查看文末了解数据获取方式)可以追溯到1988年,由四个数据库组成。克利夫兰、匈牙利、瑞士和长滩。"目标 "字段是指病人是否有心脏病。它的数值为整数,0=无病,1=有病。 目标: ...

R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
原文链接:http://tecdat.cn/?p=23061 数据集信息: 这个数据集可以追溯到1988年,由四个数据库组成。克利夫兰、匈牙利、瑞士和长滩。"目标 "字段是指病人是否有心脏病。它的数值为整数,0=无病,1=有病。 目标: 主要目的是...

R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病-2
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病-1 https://developer.aliyun.com/article/1489347 执行机器学习算法 Logistic回归 首先,我们将数据集分为训练数据(75%)和测试数据(25%)。 ...

R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病-1
原文链接:http://tecdat.cn/?p=23061 数据集信息: 这个数据集可以追溯到1988年,由四个数据库组成。克利夫兰、匈牙利、瑞士和长滩。"目标 "字段是指病人是否有心脏病。它的数值为整数,0=无病,1=有病。 目标: 主要目的是预测给定的人是否有心脏病,借助于几个因素,如年龄、胆...
[帮助文档] 什么是随机森林回归算法(RandomForestRegression)
本文介绍了随机森林回归算法(Random Forest Regression)相关内容。

使用Python实现随机森林算法
随机森林(Random Forest)是一种强大的集成学习算法,它通过组合多个决策树来进行分类或回归。在本文中,我们将使用Python来实现一个基本的随机森林分类器,并介绍其原理和实现过程。 什么是随机森林算法? 随机森林是一种集成学习方法,它通过构建多个决策树并取其投票结果(分类问题...
大模型开发:解释随机森林算法以及它是如何做出决策的。
随机森林算法是一种集成学习方法,它基于决策树构建,并通过组合多个决策树的预测结果来提高整体模型的性能。在随机森林中,每个决策树都是一个弱分类器,它们各自独立地从原始数据集中随机抽取样本和特征进行训练。最终,随机森林的决策是通过整合所有决策树的预测结果得出的。 具体来说,随机森林算法的工作流程如下: ...

随机森林算法是如何通过构建多个决策树并将它们的预测结果进行投票来做出最终的预测的?
随机森林算法通过构建多个决策树并将它们的预测结果进行投票来做出最终的预测。具体步骤如下: 数据集分割:首先,将原始数据集分成k个子集(通常选择k等于训练样本的数量)。每个子集都是通过有放回地从原始数据集中随机抽取样本得到的。这样可以确保每个子集都包含一定比例的类别平衡。 决策树构建:对于每个子集,使...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









