NLP中的预处理:使用Python进行文本归一化(一)
了解我们的目标——为什么我们需要文本归一化 让我们从归一化技术的明确定义开始。自然语言作为一种人力资源,倾向于遵循其创造者随机性的内在本质。这意味着,当我们“产生”自然语言时,我们会在其上加上随机状态。计算机不太擅长处理随机性(尽管使用机器学习算法已将随机性的影响...
一文速学-特征数据类别分析与预处理方法详解+Python代码
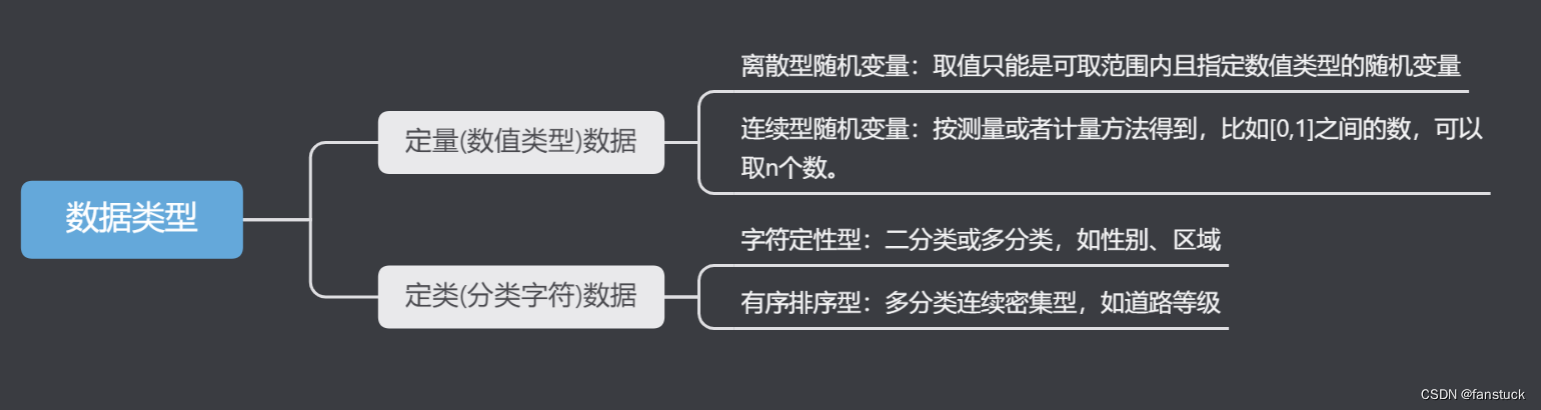
前言当我们开始准备数据建模、构建机器学习模型的时候,第一时间考虑的不应该是就考虑到选择模型的种类和方法。而是首先拿到特征数据和标签数据进行研究,挖掘特征数据包含的信息以及思考如何更好的处理这些特征数据。那么数据类型本身代表的含义就需要我们进行思考,究竟是定量计算还是进行定类分析更好呢?这就是这篇文章...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。