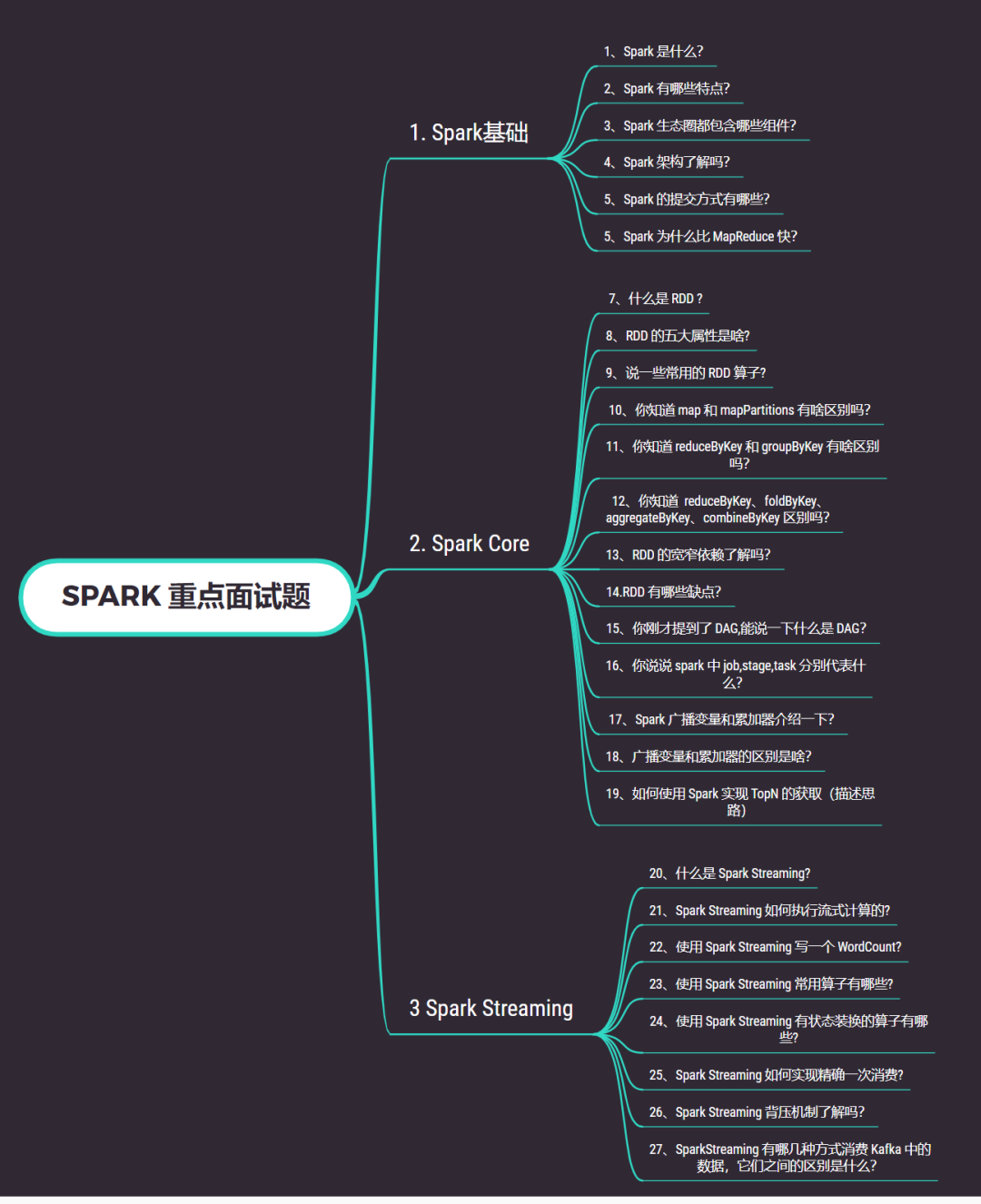
Spark面试干货总结!(8千字长文、27个知识点、21张图)
都说金九银十是找工作的绝佳时期,那现在土哥就以面试的方式为大家总结 Spark 面试所涉及的基础知识点。主要从以下 3 个方面进行分析,大纲如下:一、Spark 基础篇1、Spark 是什么?Spark 是一个通用分布式内存计算引擎。2009 年在加州大学伯克利分校 AMP 实验室诞生,2014 年...
这......Spark面试题完全不会啊!
1.什么是 Apache Spark? 它有什么特点?Apache Spark是一个分布式计算框架,它可以在大 规模数据集上进行高效的数据处理和分析。它最初由加州大学伯克利分校的AMPLab开发,并于2013年成为Apache软件基金会的顶级项目。Apache Spark的特点包括:快速:相比于传统...

spark 几道面试题
Spark与mapreduce的区别?spark on yarn client模式与cluster的区别?spark 的三种shuffle ?spark sql三种join方式?RDD有什么缺陷?Checkpoint 和持久化机制的区别?groupByKey和reduceByKey区别?为什么Spa...
Spark性能调优-RDD算子调优篇(深度好文,面试常问,建议收藏) (一)
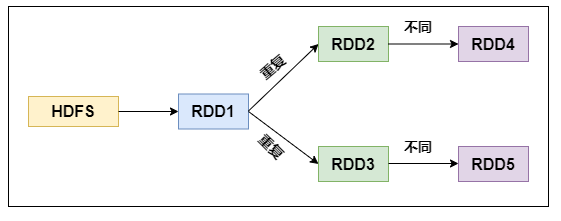
RDD算子调优不废话,直接进入正题!1. RDD复用在对RDD进行算子时,要避免相同的算子和计算逻辑之下对RDD进行重复的计算,如下图所示:对上图中的RDD计算架构进行修改,得到如下图所示的优化结果:2. 尽早filter获取到初始RDD后,应该考虑尽早地过滤掉不需要的数据...
Spark面试题(二)
1、Spark有哪两种算子?Transformation(转化)算子和Action(执行)算子。2、Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?在我们的开发过程中,能避免则尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle...

Spark面试题(五)——数据倾斜调优
1、数据倾斜数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。数据倾斜俩大直接致命后果。1、数据倾斜直接会导致一种情况:Out Of Memory。2、运行速度慢。主要是发生在Sh...
Spark面试题(八)——Spark的Shuffle配置调优
1、Shuffle优化配置 -spark.shuffle.file.buffer默认值:32k参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁...
Spark面试
1、简答说一下hadoop的map-reduce编程模型 首先map task会从本地文件系统读取数据,转换成key-value形式的键值对集合 使用的是hadoop内置的数据类型,比如longwritable、text等 将键值对集合输入mapper进行业务处理过程,将其转换成需要的key-val...
Hadoop/Spark相关面试问题总结
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq1010885678/article/details/46916857 Hadoop/Spark相关面试问题总结 面试回来之后把其中比较重要的问题记了下来写了个总结: (答案在后面) 1、简答说一下...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






