[帮助文档] 创建工作空间
工作空间是Serverless Spark的基本单元,用于管理任务、成员、角色和权限。所有的任务开发都需要在具体的工作空间内进行。因此,在开始任务开发之前,您需要先创建工作空间。本文将为您介绍如何在EMR Serverless Spark页面快速创建工作空间。
[帮助文档] Spark SQL任务快速入门
EMR Serverless Spark支持通过SQL代码编辑和运行任务。本文带您快速体验Spark SQL任务的创建、启动和运维等操作。

[帮助文档] RAM用户授权
当RAM用户(子账号)进行EMR Serverless Spark操作,例如创建、查看或删除工作空间等操作时,必须具有相应的权限。本文为您介绍如何进行RAM授权。
[帮助文档] PySpark任务开发入门
您可以自行编写并构建包含业务逻辑的Python脚本,上传该脚本后,即可便捷地创建和执行PySpark任务。本文通过一个示例,为您演示如何进行PySpark任务的开发与部署。
[帮助文档] 阿里云账号角色授权
使用EMR Serverless Spark前,需要授予您的阿里云账号AliyunServiceRoleForEMRServerlessSpark和AliyunEMRSparkJobRunDefaultRole系统默认角色。本文为您介绍角色授权的基本操作。
大数据技术与Python:结合Spark和Hadoop进行分布式计算
随着互联网的普及和技术的飞速发展,大数据已经成为当今社会的重要资源。大数据技术是指从海量数据中提取有价值信息的技术,它包括数据采集、存储、处理、分析和挖掘等多个环节。Python作为一种功能强大、简单易学的编程语言,在数据处理和分析领域具有广泛的应用。本文将介绍如何使用Python结合Spark和H...
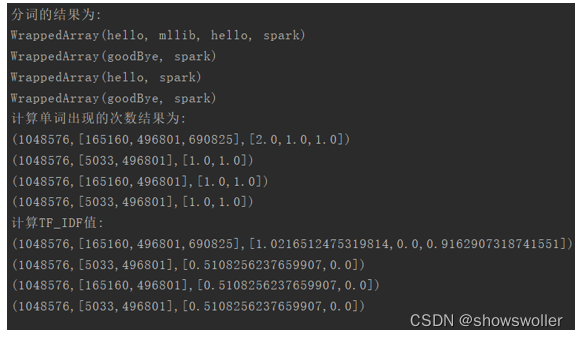
【大数据技术】Spark MLlib机器学习特征抽取 TF-IDF统计词频实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~特征抽取 TF-IDFTF-IDF是两个统计量的乘积,即词频(Term Frequency, TF)和逆向文档频率(Inverse Document Frequency, IDF)。它们各自有不同的计算方法。TF是一个文档(去除停用词之后)中某个词...
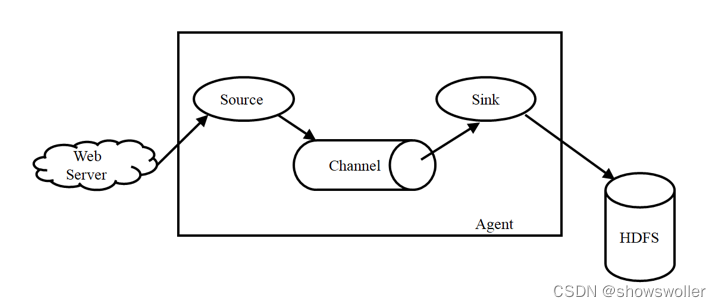
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:...
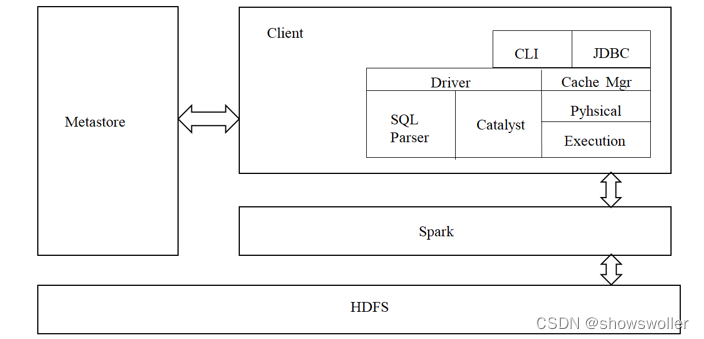
【大数据技术Hadoop+Spark】Spark SQL、DataFrame、Dataset的讲解及操作演示(图文解释)
一、Spark SQL简介park SQL是spark的一个模块,主要用于进行结构化数据的SQL查询引擎,开发人员能够通过使用SQL语句,实现对结构化数据的处理,开发人员可以不了解Scala语言和Spark常用API,通过spark SQL,可以使用Spark框架提供的强大的数据分析能力。spark...
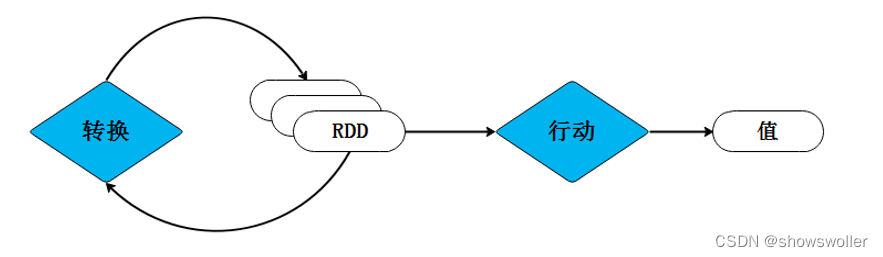
【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建R...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark Hadoop
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作