【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
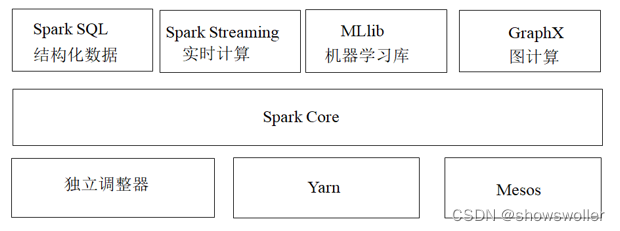
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心...
【大数据技术Hadoop+Spark】Hive基础SQL语法DDL、DML、DQL讲解及演示(附SQL语句)
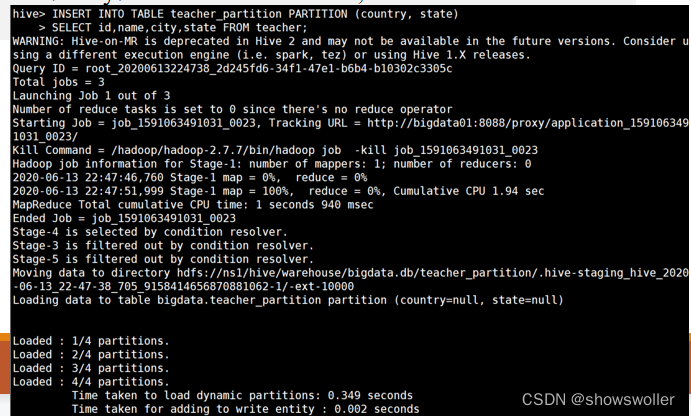
Hive基础SQL语法1:DDL操作DDL是数据定义语言,与关系数据库操作相似,创建数据库CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name显示数据库SHOW databases;查看数据库详情DESC DATABASE|SCHEMA datab...

【大数据技术Hadoop+Spark】MapReduce概要、思想、编程模型组件、工作原理详解(超详细)
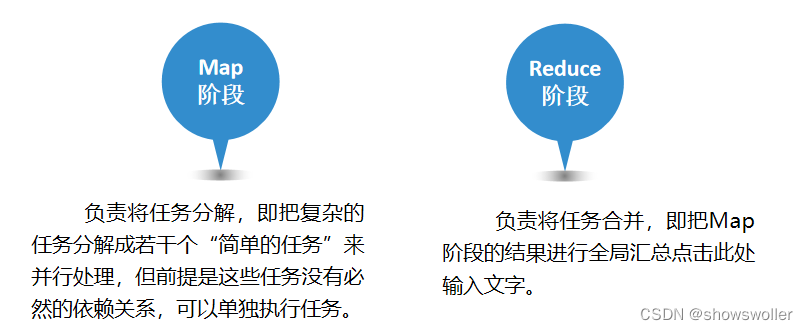
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。一、MapReduce核心思想MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方...
【云计算与大数据技术】Spark的解析(图文解释 超详细必看)
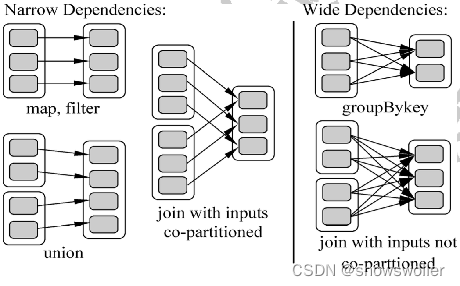
一、Spark RDDSpark是一个高性能的内存分布式计算框架,具备可扩展性,任务容错等特性,每个Spark应用都是由一个driver program 构成,该程序运行用户的 main函数 。Spark提供的一个主要抽象就是 RDD(Resilient Distributed Datasets),...
史上最快! 10小时大数据入门实战(九)- 前沿技术拓展Spark,Flink,Beam
spark Spark 开发语言及运行模式介绍 Scala安装 下载 Scala 配置到系统环境变量 配置成功 Spark环境搭建及 wordCount 案例实现 下载 spark 解压编译 spark...
开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启。通过封神了解到,在上午的专场中,阿里云高级技术专家无谓、阿里云技术专家封神、阿里巴巴中间件技术部高级技术专家天梧、阿里巴巴中间件技术部资深技术专家纪君祥将给大家带来Hadoop、Spark、HBase、...
最全的大数据技术大合集:Hadoop家族、Cloudera系列、spark
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来。为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选择合适的技术,了解大数据各种技术之间的关系,选择合适的语言。 我们可以带着下面问题来阅读本文章: 1...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark大数据计算
- apache spark client
- apache spark报错
- apache spark模式
- apache spark任务
- apache spark Hive
- apache spark SQL
- apache spark yarn
- apache spark MaxCompute
- apache spark like
- apache spark streaming
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark rdd
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala