
数据分享|基于Python、Hadoop零售交易数据的Spark数据处理与Echarts可视化分析
全文链接:http://tecdat.cn/?p=29528 分析师:Enno 案例数据集是在线零售业务的交易数据,采用Python为编程语言,采用Hadoop存储数据,采用Spark对数据进行处理分析,并使用Echarts做数据可视化。由于案例公司商业模式类似新零售,或者说有向此方向发展利好的趋势...
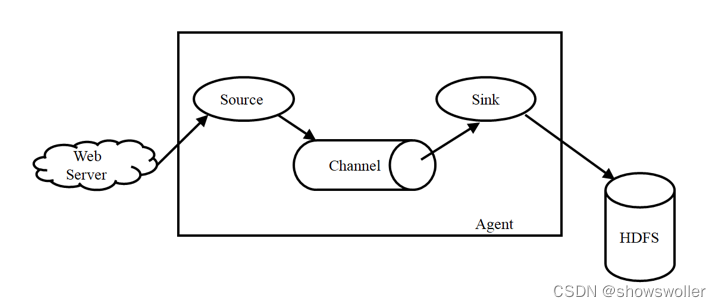
【大数据技术Hadoop+Spark】Flume、Kafka的简介及安装(图文解释 超详细)
Flume简介Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume主要由3个重要的组件构成:1)Source:...

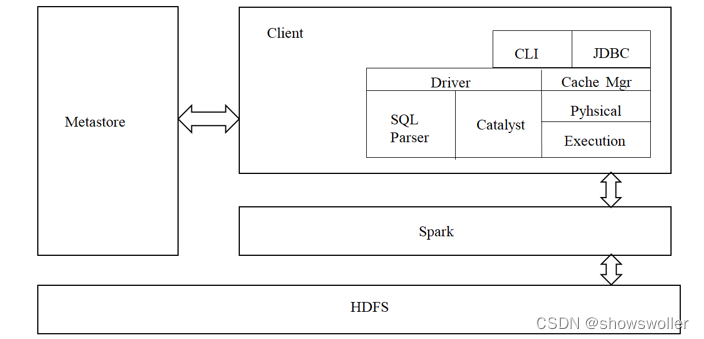
【大数据技术Hadoop+Spark】Spark SQL、DataFrame、Dataset的讲解及操作演示(图文解释)
一、Spark SQL简介park SQL是spark的一个模块,主要用于进行结构化数据的SQL查询引擎,开发人员能够通过使用SQL语句,实现对结构化数据的处理,开发人员可以不了解Scala语言和Spark常用API,通过spark SQL,可以使用Spark框架提供的强大的数据分析能力。spark...
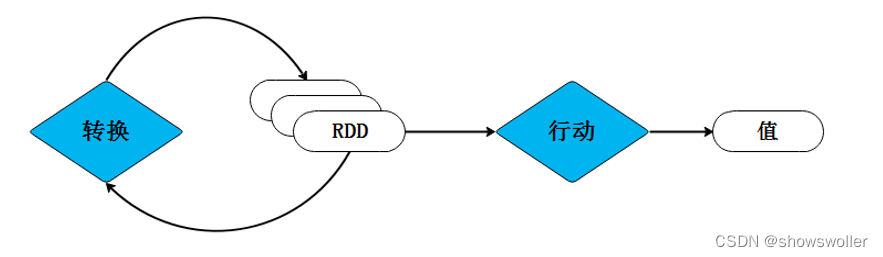
【大数据技术Hadoop+Spark】Spark RDD创建、操作及词频统计、倒排索引实战(超详细 附源码)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~一、RDD的创建Spark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统。我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。1、从文件系统加载数据创建R...
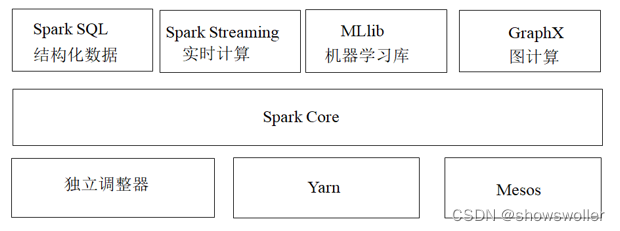
【大数据技术Hadoop+Spark】Spark架构、原理、优势、生态系统等讲解(图文解释)
一、Spark概述Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心...
【大数据技术Hadoop+Spark】Hive基础SQL语法DDL、DML、DQL讲解及演示(附SQL语句)
Hive基础SQL语法1:DDL操作DDL是数据定义语言,与关系数据库操作相似,创建数据库CREATE DATABASE|SCHEMA [IF NOT EXISTS] database_name显示数据库SHOW databases;查看数据库详情DESC DATABASE|SCHEMA datab...

【云计算与大数据计算】分布式处理CPU多核、MPI并行计算、Hadoop、Spark的简介(超详细)
一、CPU多核和POISX Thread为了提高任务的计算处理能力,下面分别从硬件和软件层面研究新的计算处理能力在硬件设备上,CPU 技术不断发展,出现了SMP(对称多处理器)和 NUMA(非一致 性内存访问)两种高速处理的 CPU 结构 在软件层面出现了多进程和多线程编程。进程是内存资源管理单元,...

大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
一、概述Hudi(Hadoop Upserts Deletes and Incrementals),简称Hudi,是一个流式数据湖平台,支持对海量数据快速更新,内置表格式,支持事务的存储层、 一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具,它可以以极低的延迟将数据快...
Hadoop生态系统中的机器学习与数据挖掘技术:Apache Mahout和Apache Spark MLlib的应用
Hadoop是一个开源的分布式计算框架,用于处理大规模数据集的存储和处理。随着大数据的快速发展,机器学习和数据挖掘技术在Hadoop生态系统中的应用也变得越来越重要。在本文中,我们将重点介绍Hadoop生态系统中的两个重要机器学习和数据挖掘技术:Apache Mahout和Apache Spark ...
Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较
Hadoop生态系统中的流式数据处理技术:Apache Flink和Apache Spark的比较 引言:在大数据时代,处理海量的实时数据变得愈发重要。Hadoop生态系统中的两个主要的流式数据处理框架,Apache Flink和Apache Spark,都提供了强大的功能来应对这一挑战。本文将对这...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache sparkhadoop相关内容
- apache spark hadoop区别
- hadoop apache spark异同
- hadoop apache spark特点
- 系统hadoop apache spark
- hadoop apache spark技术
- hadoop apache spark区别
- 大数据开发hadoop apache spark
- hadoop apache spark项目案例
- hadoop apache spark storm
- apache spark Hadoop大数据分析
- apache spark Hadoop大数据导读
- apache spark Hadoop大数据
- apache spark Hadoop大数据资源管理器
- apache spark Hadoop大数据应用程序
- apache spark Hadoop大数据小结
- apache spark Hadoop大数据结合使用
- apache spark hadoop大数据分析宏观视角
- hadoop apache spark项目
- 读懂hadoop apache spark异同
- apache spark Hadoop项目
- apache spark hadoop集群
- apache spark核心思想源码分析hadoop配置executor
apache spark您可能感兴趣
- apache spark数据
- apache spark分析
- apache spark Python
- apache spark可视化
- apache spark数据处理
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark SQL
- apache spark streaming
- apache spark Apache
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark实战
- apache spark机器学习
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作