矢量数据库与大数据平台的集成:实现高效数据处理
一、引言 在大数据时代,数据已成为企业的重要资产。然而,随着数据量的不断增长和数据类型的多样化,如何高效地处理和分析这些数据成为了一个挑战。矢量数据库以其独特的优势,如高效存储、检索和处理空间数据的能力,成为大数据处理领域的一个重要组成部分。本文将探讨矢量数据库与大数据平台的集成,以及如何通过集成实...
Pandas与其他库的集成:构建强大的数据处理生态
在数据处理的领域中,Pandas以其强大的数据结构和灵活的操作成为了不可或缺的工具。然而,仅仅依靠Pandas并不足以应对所有数据处理和分析的挑战。幸运的是,Pandas与众多其他Python库的无缝集成,使得我们可以构建一个强大的数据处理生态,从而更加高效地完成各种复杂任务。 一、Pandas与N...

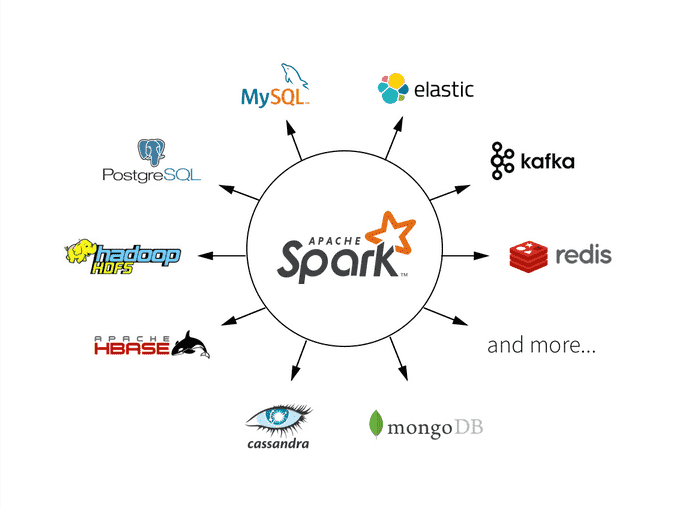
Spark与Kafka的集成与流数据处理
Apache Spark和Apache Kafka是大数据领域中非常流行的工具,用于数据处理和流数据处理。本文将深入探讨如何在Spark中集成Kafka,并演示如何进行流数据处理。将提供丰富的示例代码,以帮助大家更好地理解这一集成过程。 Spark与Kafka的基本概念 在开始集成之前,首先了解一下...
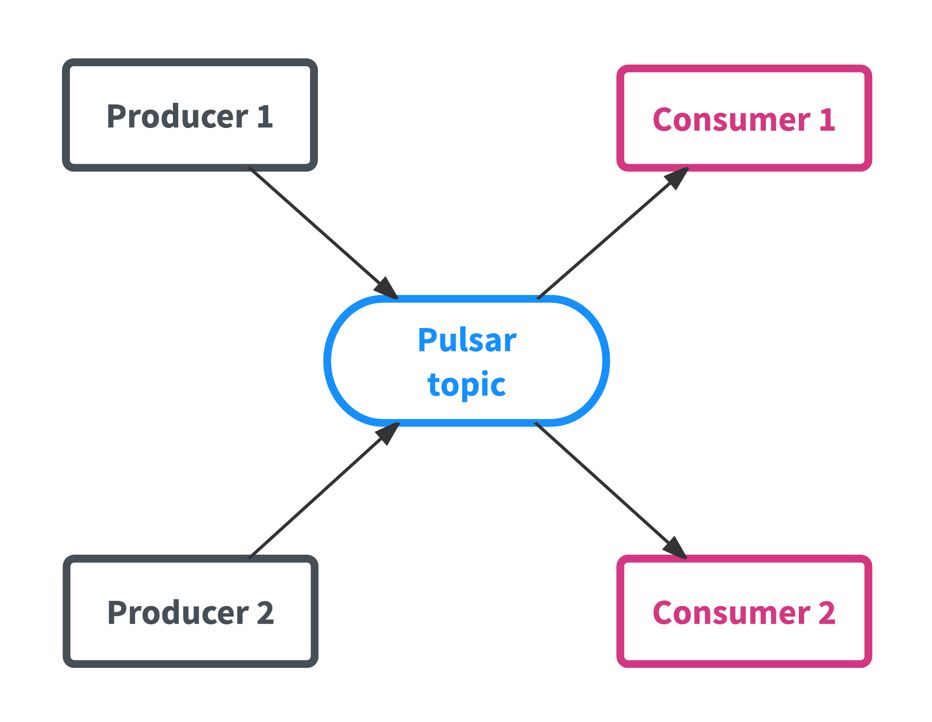
Flink未来-将与 Pulsar集成提供大规模的弹性数据处理
Apache Flink和Apache Pulsar的开源数据技术框架可以以不同的方式集成,以提供大规模的弹性数据处理。 在这篇文章中,我将简要介绍Pulsar及其与其他消息传递系统的差异化元素,并描述Pulsar和Flink可以协同工作的方式,为大规模弹性数据处理提供无缝的开...
[帮助文档] 从Oracle抽数据到Hive,Date类型数据处理出现脏数据
问题描述Dataphin集成任务从Oracle 抽数据到 Hive,过滤组件中对Date类型数据处理出现脏数据。{ "category":"filter", "distribute":true, "name":"WH...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








