[帮助文档] 如何训练GPT-2模型并生成文本
本文介绍如何使用GPU云服务器,使用Megatron-Deepspeed框架训练GPT-2模型并生成文本。
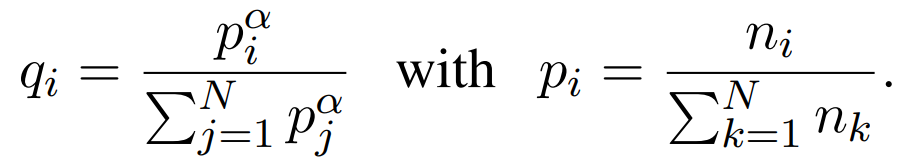
GPT、BERT、XLM、GPT-2、BART…你都掌握了吗?一文总结文本生成必备经典模型(2)
Cross-lingual Language Model Pretraining BERT模型可以在上百种语言上进行预训练,语言之间的信息并不是互通的,不同的语言模型之间没有共享知识。Facebook的XLM模型克服了信息不互通的难题,它将不同语言放在一起采用新的训练目标进行训...
GPT、BERT、XLM、GPT-2、BART…你都掌握了吗?一文总结文本生成必备经典模型(1)
机器之心专栏本专栏由机器之心SOTA!模型资源站出品,每周日于机器之心公众号持续更新。 本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取...
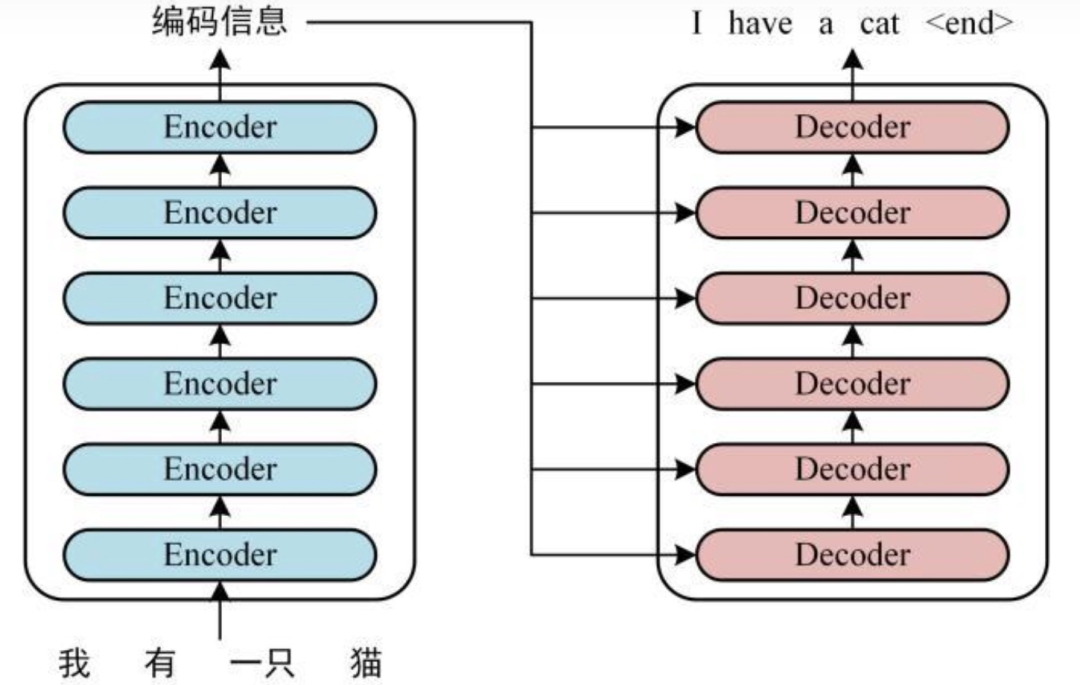
ELMo、GPT、BERT、X-Transformer…你都掌握了吗?一文总结文本分类必备经典模型(五)
二、Transformer基于Transformer的模型可以在不考虑顺序信息的情况下将计算并行化,适用于大规模的数据集,使其在NLP任务中很受欢迎。Transformer由17年一篇著名论文“Attention is All Your Need”提出的。在这篇论文中,作者提出了一种全新的注意力机制...
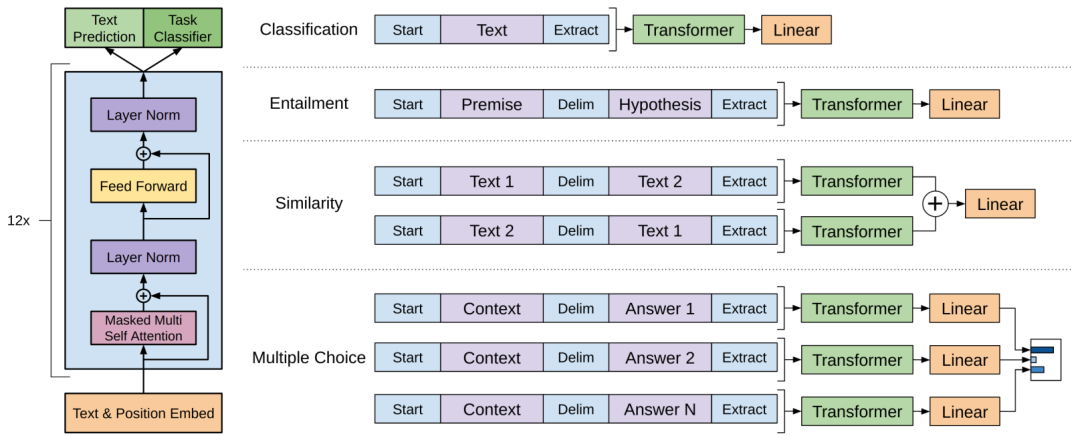
ELMo、GPT、BERT、X-Transformer…你都掌握了吗?一文总结文本分类必备经典模型(四)
1.2 GPTGPT是“Generative Pre-Training”的简称,是指的生成式的预训练。GPT的训练程序包括两个阶段。第一阶段的预训练是在一个大型文本语料库上学习一个高容量的语言模型。接下来是一个微调阶段,在这个阶段,使模型适应带有标记数据的判别性任务。第一阶段的工作具体为:Embed...
ELMo、GPT、BERT、X-Transformer…你都掌握了吗?一文总结文本分类必备经典模型(三)
本文将分 3 期进行连载,共介绍 20 个在文本分类任务上曾取得 SOTA 的经典模型。第 1 期:RAE、DAN、TextRCNN、Multi-task、DeepMoji、RNN-Capsule第 2 期:TextCNN、DCNN、XML-CNN、TextCapsule、、Bao et ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
