[帮助文档] MaxCompute近实时数仓数据入仓介绍
为满足业务对数据仓库中高度时效性数据的需求,MaxCompute基于Delta Table实现了分钟级近实时数据写入和主键更新功能,显著提升了数据仓库的数据更新效率。
[帮助文档] 迁移StarRocks数据至EMR Serverless StarRocks
本文将指导您如何使用StarRocks跨集群数据迁移工具,在源集群保持在线且业务服务不中断的状态下高效、安全地进行数据复制。该工具提供全量及增量同步功能,旨在为您提供一键式解决方案,实现源集群数据无缝迁移至目标集群,确保数据一致性的同时,最大限度减少对业务运营的影响。

大数据计算MaxCompute使用mma迁移hive数据,这个问题应该如何处理呀?
大数据计算MaxCompute使用mma迁移hive数据,注册了hive UDTF,在mma执行迁移任务的时候提示函数无效,拿到迁移的sql到hive 控制台是能正常执行的,这个问题应该如何处理呀?hive元数据也更新了。Caused by: java.lang.RuntimeException: ...
[帮助文档] 通过MaxCompute控制台上传数据
MaxCompute控制台提供数据上传功能,支持您将本地文件或阿里云对象存储服务OSS中的文件数据离线(非实时)上传至MaxCompute进行分析处理及相关管理操作。
[帮助文档] Java SDK大数据场景下批量写入数据
表格存储提供了BulkImport接口用于在大数据场景下批量写入数据到数据表。当要写入数据到数据表时,您需要指定完整主键以及要增删改的属性列。
[帮助文档] 数据洞察生成数据卡片及报告
DataWorks数据洞察是指通过深度数据分析和解读来获取深刻的数据理解和发现,它支持数据探索和可视化。您可以通过数据洞察了解数据分布,创建数据卡片,并组合成数据报告。此外,数据洞察结果能够通过长图形式的报告进一步分享。该功能利用AI技术辅助数据分析,帮助您解析复杂数据,并为业务决策提供支持。
Apache Flink目前不支持直接写入MaxCompute,但是可以通过Hive Catalog将Flink的数据写入Hive表
Apache Flink目前不支持直接写入MaxCompute,但是可以通过Hive Catalog将Flink的数据写入Hive表,然后再通过Hive与MaxCompute的映射关系将数据同步到MaxCompute。 首先,你需要在Flink中配置Hive Catalog,然后创建一个Hive表,...
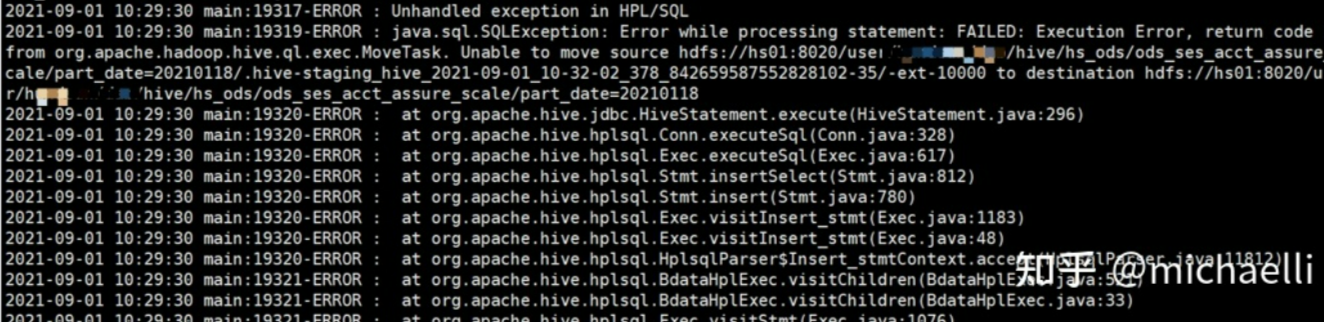
大数据问题排查系列 - 因HIVE 中元数据与HDFS中实际的数据不一致引起的问题的修复
大数据问题排查系列 - 因HIVE 中元数据与HDFS中实际的数据不一致引起的问题的修复前言大家好,我是明哥!本片博文是“大数据问题排查系列”之一,讲述某HIVE SQL 作业因为 HIVE 中的元数据与 HDFS中实际的数据不一致引起的一个问题的排查和修复。以下是正文。问题现象客户端报错如下:Un...
大数据Hive数据操纵语言DML
1 背景:RDBMS中insert使用(insert+values)在MySQL这样的RDBMS中,通常是insert+values的方式来向表插入数据,并且速度很快。这也是RDBMS中插入数据的核心方式。INSERT INTO table_name ( field1, field2,...fiel...
大数据计算MaxCompute adb通过外部表读取hive数据进行查询分析,无需存储就能查询吗?
大数据计算MaxCompute adb通过外部表读取hive数据进行查询分析,无需存储就能查询吗?
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









云原生大数据计算服务 MaxCompute数据相关内容
- 云原生大数据计算服务 MaxCompute where数据
- 云原生大数据计算服务 MaxCompute查询数据
- 云原生大数据计算服务 MaxCompute udf数据
- 云原生大数据计算服务 MaxCompute上传数据数据
- 云原生大数据计算服务 MaxCompute tunnel数据
- 云原生大数据计算服务 MaxCompute tunnel命令数据
- 云原生大数据计算服务 MaxCompute命令数据
- 云原生大数据计算服务 MaxCompute格式数据
- 云原生大数据计算服务 MaxCompute命令下载数据
- 云原生大数据计算服务 MaxCompute数据超时
- 云原生大数据计算服务 MaxCompute tunnel下载数据
- 云原生大数据计算服务 MaxCompute download数据
- 访问云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute下载数据
- 云原生大数据计算服务 MaxCompute download下载数据
- 云原生大数据计算服务 MaxCompute分区数据
- 云原生大数据计算服务 MaxCompute pyodps数据
- 云原生大数据计算服务 MaxCompute sql数据
- 云原生大数据计算服务 MaxCompute数据报错
- 云原生大数据计算服务 MaxCompute类型数据
- 云原生大数据计算服务 MaxCompute字段数据
- 云原生大数据计算服务 MaxCompute节点数据
- 云原生大数据计算服务 MaxCompute mr数据
- 云原生大数据计算服务 MaxCompute mr类型数据
- 大数据计算云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute分区查询数据
- 云原生大数据计算服务 MaxCompute数据sql
- 云原生大数据计算服务 MaxCompute库数据
- 数据计算云原生大数据计算服务 MaxCompute数据分区
- 数据计算云原生大数据计算服务 MaxCompute分区表数据
- 云原生大数据计算服务 MaxCompute分区表数据
- 云原生大数据计算服务 MaxCompute数据分区
- 云原生大数据计算服务 MaxCompute mysql数据
- 大数据云原生大数据计算服务 MaxCompute办法数据
- 云原生大数据计算服务 MaxCompute办法数据
- 云原生大数据计算服务 MaxCompute数据计费
- 云原生大数据计算服务 MaxCompute增量数据
- 云原生大数据计算服务 MaxCompute数据mc
- 云大数据云原生大数据计算服务 MaxCompute
- 数据云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute数据文件
- 云原生大数据计算服务 MaxCompute设置数据
- 云原生大数据计算服务 MaxCompute rds数据
- 数据计算云原生大数据计算服务 MaxCompute外部表数据
- 云原生大数据计算服务 MaxCompute外部表数据
- 云原生大数据计算服务 MaxCompute任务数据
- 云原生大数据计算服务 MaxCompute odpssql数据
- 云原生大数据计算服务 MaxCompute抽取数据
- 云原生大数据计算服务 MaxCompute mma数据
云原生大数据计算服务 MaxCompute更多数据相关
- dataworks数据云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute存储数据
- maxcompute云原生大数据计算服务 MaxCompute数据
- dataworks云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute模型数据
- 云原生大数据计算服务 MaxCompute数据oss
- 云原生大数据计算服务 MaxCompute产品架构计算模型数据
- 云原生大数据计算服务 MaxCompute迁移数据
- 云原生大数据计算服务 MaxCompute maxcompute tunnel数据
- 云原生大数据计算服务 MaxCompute结构化数据
- 云原生大数据计算服务 MaxCompute数据网络世界学术
- 大数据云原生大数据计算服务 MaxCompute数据存储
- 云原生大数据计算服务 MaxCompute spark数据
- spark云原生大数据计算服务 MaxCompute数据
- 云原生大数据计算服务 MaxCompute方法数据
- 数据数据计算云原生大数据计算服务 MaxCompute
- 数据计算云原生大数据计算服务 MaxCompute数据oss
- 云原生大数据计算服务 MaxCompute dataworks数据
- 云原生大数据计算服务 MaxCompute mc数据
- 云原生大数据计算服务 MaxCompute函数数据
- 大数据云原生大数据计算服务 MaxCompute下载数据
- 云原生大数据计算服务 MaxCompute数据配置
- 云原生大数据计算服务 MaxCompute数据采集数据来源
- 云原生大数据计算服务 MaxCompute项目数据
- 查询云原生大数据计算服务 MaxCompute数据
- 数据云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute数据设置
- 云原生大数据计算服务 MaxCompute sqoop数据
- 云原生大数据计算服务 MaxCompute连接数据
- 云原生大数据计算服务 MaxCompute数据优化
- 云原生大数据计算服务 MaxCompute产品数据
- 云原生大数据计算服务 MaxCompute同步数据hologres
- 云原生大数据计算服务 MaxCompute json数据
- 云原生大数据计算服务 MaxCompute数据办法
- 日志服务数据云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute数据区别
- 大数据云原生大数据计算服务 MaxCompute数据配置
- 云原生大数据计算服务 MaxCompute数据下载
- 云原生大数据计算服务 MaxCompute数据字段
- 云原生大数据计算服务 MaxCompute数据运行
- es数据云原生大数据计算服务 MaxCompute
- 云原生大数据计算服务 MaxCompute insert数据
- rds数据云原生大数据计算服务 MaxCompute
- 实时同步数据云原生大数据计算服务 MaxCompute
- 数据计算云原生大数据计算服务 MaxCompute查询数据
- 数据计算云原生大数据计算服务 MaxCompute下载数据
- 云原生大数据计算服务 MaxCompute数据上云
- 数据计算云原生大数据计算服务 MaxCompute odps数据
- 云原生大数据计算服务 MaxCompute数据hive
- 云原生大数据计算服务 MaxCompute数据程序
云原生大数据计算服务 MaxCompute您可能感兴趣
- 云原生大数据计算服务 MaxCompute如何处理
- 云原生大数据计算服务 MaxCompute pyodps
- 云原生大数据计算服务 MaxCompute ddl
- 云原生大数据计算服务 MaxCompute failed
- 云原生大数据计算服务 MaxCompute sql
- 云原生大数据计算服务 MaxCompute数据表
- 云原生大数据计算服务 MaxCompute生命周期
- 云原生大数据计算服务 MaxCompute region
- 云原生大数据计算服务 MaxCompute schema
- 云原生大数据计算服务 MaxCompute计算
- 云原生大数据计算服务 MaxCompute MaxCompute
- 云原生大数据计算服务 MaxCompute大数据计算
- 云原生大数据计算服务 MaxCompute dataworks
- 云原生大数据计算服务 MaxCompute分析
- 云原生大数据计算服务 MaxCompute应用
- 云原生大数据计算服务 MaxCompute阿里云
- 云原生大数据计算服务 MaxCompute技术
- 云原生大数据计算服务 MaxCompute表
- 云原生大数据计算服务 MaxCompute报错
- 云原生大数据计算服务 MaxCompute spark
- 云原生大数据计算服务 MaxCompute大数据
- 云原生大数据计算服务 MaxCompute同步
- 云原生大数据计算服务 MaxCompute任务
- 云原生大数据计算服务 MaxCompute查询
- 云原生大数据计算服务 MaxCompute hadoop
- 云原生大数据计算服务 MaxCompute平台
- 云原生大数据计算服务 MaxCompute项目