[帮助文档] 通过实时数据消费将Kafka数据写入AnalyticDB PostgreSQL
当您需要将Kafka数据写入云原生数据仓库AnalyticDB PostgreSQL版,且不希望使用其他数据集成工具时,可以通过实时数据消费功能直接消费Kafka数据,减少实时处理组件依赖,提升写入吞吐。
[帮助文档] Data Exchange提供集成和转换工具, 以帮助用户更好地订阅数据产品、使用数据产品。用户可以使用这些工具将数据产品与其现有的数据架构集成, 或者对数据进行必要的转换和加工, 以满足特定的业务需求
Data Exchange提供集成和转换工具,以帮助用户更好地订阅数据产品、使用数据产品。用户可以使用这些工具将数据产品与其现有的数据架构集成,或者对数据进行必要的转换和加工,以满足特定的业务需求。第一步:订阅数据集进入云市场,查找感兴趣的数据集商品,进行选购。云市场第二步:查看数据集订阅后,可进入...

[帮助文档] 使用数据集成服务迁移数据到表格存储
当您的现有业务对数据库的并发读写、扩展性和可用性的要求较高,且需要使用复杂的检索或大数据分析时,如果原有数据库的数据架构不能满足现在的业务需求或改造成本较大,则您可以通过DataWorks数据集成服务将现有数据库中的数据迁移到Tablestore表中存储和使用。您还可以通过DataWorks数据集成...

R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
特别是在经济学/计量经济学中,建模者不相信他们的模型能反映现实。比如:收益率曲线并不遵循三因素的Nelson-Siegel模型,股票与其相关因素之间的关系并不是线性的,波动率也不遵循Garch(1,1)过程,或者Garch(?,?)。我们只是试图为我们看到的现象找到一个合适的描述。 模型的发展往往不...
[帮助文档] CloudFlow集成OTS实现流程中各种数据的读写和持久化存储
云工作流可以在流程中集成表格存储(Tablestore),通过集成Tablestore,您可以将流程运行中的各种数据持久化到Tablestore的某个表中,也可以将某个表的数据作为流程的数据源。本文分别从数据读取和数据写入两种场景,介绍云工作流集成Tablestore的示例代码、参数说明和集成输出。
[帮助文档] 统计JMeter集成压测数据
PTS的JMeter集成压测使用原生JMeter引擎,其中的监控数据采集部分的数据来源是基于Backend Listener,实现了简单的聚合计算。Backend Listener
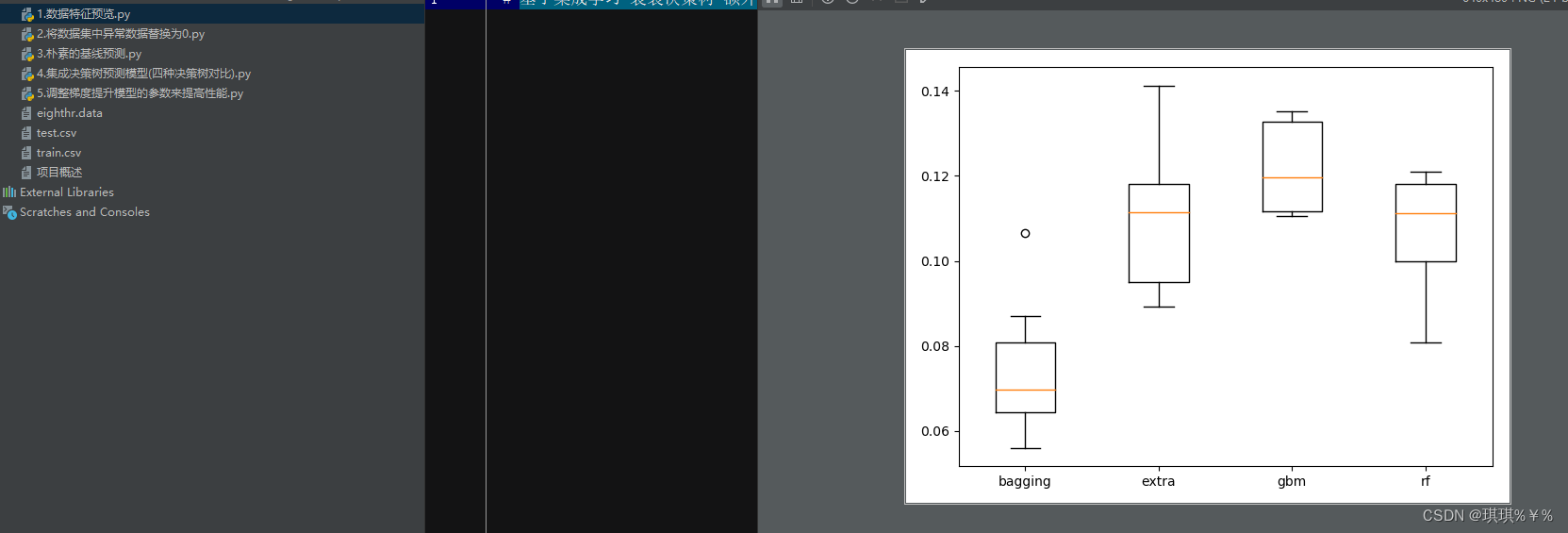
大气臭氧浓度预测:基于集成学习 袋装决策树 额外决策树 随机梯度提升 随机森林的时间序列 大气臭氧浓度预测 完整代码+数据 可直接运行
项目演示:https://www.bilibili.com/video/BV1ZM4y1m7Lg/?spm_id_from=333.999.0.0&vd_source=8f3cf4ad6c08a40d40ca6809c9c9e8ca本博客附完整的代码+数据 ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。









集成数据相关内容
- 集成同步数据hologres
- dataphin集成数据
- 集成任务数据
- 集成数据实时同步
- 集成功能数据
- 集成postgresql数据
- 集成同步postgresql数据
- 集成决策数据
- 集成树数据
- dataworks集成数据字段
- 集成数据字段
- 集成同步数据字段
- 集成同步任务数据
- dataworks集成任务数据
- 宜搭集成数据
- 钉钉集成数据
- dataworks集成数据
- 集成文件数据
- 独享集成数据
- 集成资源组数据
- dataworks集成全量数据
- 集成elasticsearch数据
- 集成抽取数据
- hbase集成数据
- 数据湖集成数据
- 任务集成数据
- 集成maxcompute数据
- 集成oss数据
- 集成json数据
- 集成数据运行
- 集成分区数据
- dataworks数据集成任务
- dataworks数据集成
- dataworks集成离线同步数据
- 集成离线同步任务数据
- dataworks集成数据去向
- dataworks集成库同步数据
- 同步数据集成
- 数据独享集成
- 集成字段数据
- dataworks集成脚本数据
- 集成名称数据
- dataworks集成实例数据
- 集成数据报错
- 集成运行数据
- 大数据maxcompute集成数据
- 集成自动化主表数据
- dataworks集成数据信息