大数据Spark RDD持久化和Checkpoint
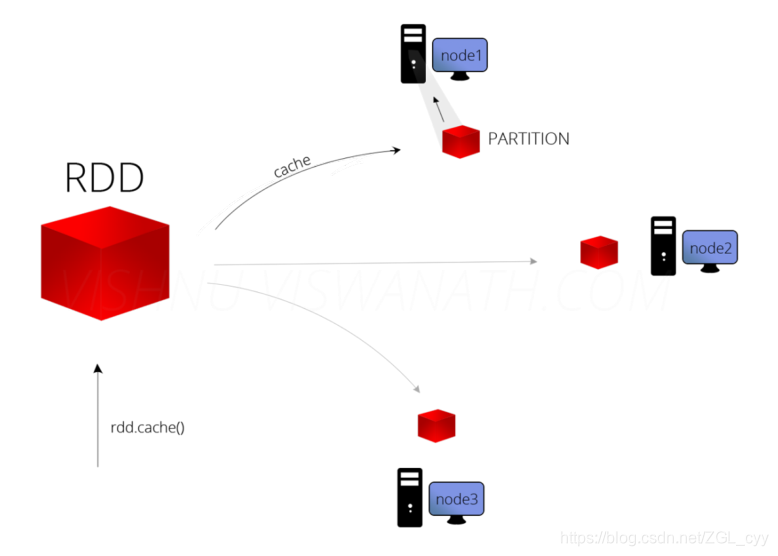
1 缓存函数在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。可以将RDD数据直接缓存到内存中,函数声明如下:但是实际项目中,不会直接使用上述的缓存函数&a...

Spark 的持久化 & Checkpoint
一、RDD 的持久化原理(cache&persist):首先明确一点,RDD 中是不存储数据的,如果一个 RDD 需要重复使用,那么需要从头执行来获取数据。所以,RDD 的持久化就是为了解决这一问题:如果需要重用 RDD 的话,可以使用 cache 或者 pers...

本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark实验
- apache spark编程
- apache spark streaming
- apache spark SQL
- apache spark实践
- apache spark rdd
- apache spark安装使用
- apache spark Hadoop
- apache spark环境搭建
- apache spark计算
- apache spark Apache
- apache spark数据
- apache spark大数据
- apache spark MaxCompute
- apache spark运行
- apache spark summit
- apache spark集群
- apache spark模式
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala
- apache spark任务
- apache spark程序