[帮助文档] 如何使用Flume同步EMR Kafka集群的数据至阿里云OSS-HDFS服务
本文为您介绍如何使用Flume同步EMR Kafka集群的数据至阿里云OSS-HDFS服务。
[帮助文档] Flume使用JindoSDK写入OSS-HDFS服务
Apache Flume是一个分布式、可靠和高可用的系统,用于从大量不同的数据源有效地收集、聚合和移动大量日志数据,进行集中式的数据存储。Flume通过调用flush()保证事务性写入,并通过JindoSDK写入OSS-HDFS服务,确保flush后的数据立刻可见,保证数据不丢失。

64 Flume采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs。根据需求,首先定义以下3大要素采集源,即source——监控文件内容更新 : exec ‘tail -F file’下沉目标,即sink——HDFS文件系统 : hdfs sinkSou...
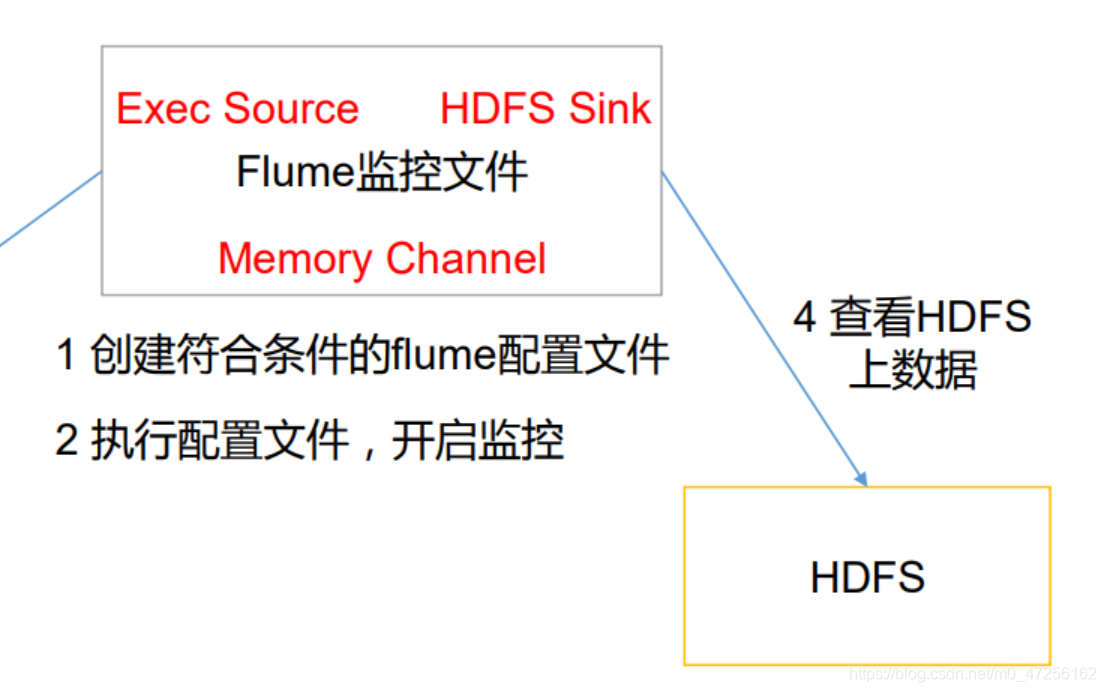
【Flume中间件】(3)实时监听文件到HDFS系统
实时监听文件到HDFS系统之前测试了监听一个文件的新内容,然后打印到了控制台,现在我们需要将监控到的内容放到HDFS中进行存储,其实和控制台一样,只不过是将sink源改到HDFS,修改一下相关的配置。a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1....

大数据编程技术基础实验八:Flume实验——文件数据Flume至HDFS
一、前言距离上次大数据编程技术基础实验已经过去二十天了,我们的课程并没有结束,是因为学校服务器关闭了一段时间,所以就一直没有做实验,今天我们就继续进行有关大数据的实验。二、实验目的掌握Flume的安装部署.掌握一个agent中source、sink、channel组件之间的关系加深对Flume结构和...
Flume实时监控日志文件到HDFS中实现的步骤是什么?
Flume实时监控日志文件到HDFS中实现的步骤是什么?
Flume实时监控日志文件到HDFS中的需求分析是什么?
Flume实时监控日志文件到HDFS中的需求分析是什么?
Flume监听文件夹中的文件变化,并把文件下沉到hdfs
1、采集目录到HDFS 采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去 根据需求,首先定义以下3大要素 采集源,即source——监控文件目录 : spooldir 下沉目标,即sink——HDFS文件系统 : hdfs sink source...
模拟使用Flume监听日志变化,并且把增量的日志文件写入到hdfs中
1.采集日志文件时一个很常见的现象 采集需求:比如业务系统使用log4j生成日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs中。 1.1.根据需求,首先定义一下3大要素: 采集源,即source—监控日志文件内容更新:exec ‘tail -F file’ 下沉目标,即sink...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。