[帮助文档] SparkSQL、Dataset和DataFrame介绍以及SparkSQL的基础操作
本文为您介绍Spark SQL、Dataset和DataFrame相关的概念,以及Spark SQL的基础操作。

数据分享|Python、Spark SQL、MapReduce决策树、回归对车祸发生率影响因素可视化分析
相关视频 项目挑战 ...

[帮助文档] Spark SQL任务快速入门
EMR Serverless Spark支持通过SQL代码编辑和运行任务。本文带您快速体验Spark SQL任务的创建、启动和运维等操作。
[帮助文档] MaxCompute计算作业成本控制
当您发现MaxCompute账单持续上涨,而且成本变得难以管理时,您可以从计算作业着手,通过对SQL作业和MapReduce作业的优化而减少计算成本。本文为您介绍SQL作业和MapReduce作业计算成本的控制方法。
[帮助文档] 如何通过SparkSQL对FlinkTableStore进行读写操作
E-MapReduce的Flink Table Store服务支持通过Spark SQL对Flink Table Store进行读写操作。本文通过示例为您介绍如何通过Spark SQL对Flink Table Store进行读写操作。
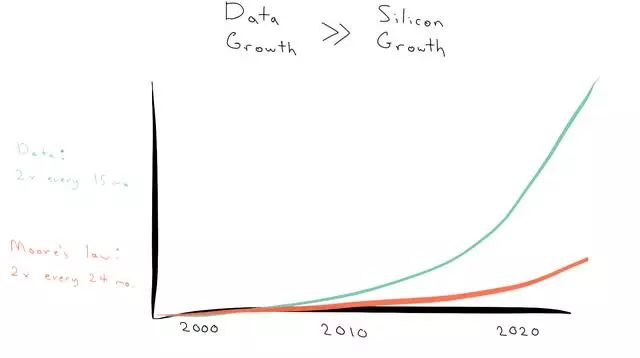
「PostgreSQL」用MapReduce的方式思考,但使用SQL
对于那些考虑使用Citus的人来说,如果您的用例看起来很合适,我们通常愿意花一些时间与您一起帮助您了解Citus数据库及其可以提供的性能类型。我们通常与我们的一位工程师进行大约两个小时的配对,以完成此操作。我们将讨论架构,加载一些数据并运行一些查询。如果最后有时间,将相同的数据和查询加载到单节点Po...
pyodps是会先转化为sql,再转化成mapreduce吗?
我看在使用pyodps的时候,控制台的输出会是一段段sql,这是否意味着其是先转化为sql再转化mapreduce任务
[帮助文档] 如何通过SparkSQL对Hudi进行读写操作
E-MapReduce的Hudi 0.8.0版本支持Spark SQL对Hudi进行读写操作,可以极大的简化Hudi的使用成本。本文为您介绍如何通过Spark SQL对Hudi进行读写操作。
Hive SQL与MaxCompute SQL在MapReduce开发上的区别是什么?
Hive SQL与MaxCompute SQL在MapReduce开发上的区别是什么?
Hive mapreduce SQL实现原理——SQL最终分解为MR任务,而group by在MR里和单词统计MR没有区别了
转自:http://blog.csdn.net/sn_zzy/article/details/43446027 SQL转化为MapReduce的过程 了解了MapReduce实现SQL基本操作之后,我们来看看Hive是如何将SQL转化为MapReduce任务的,整个编译过程分为六个阶段: Antlr...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
产品推荐
mapreduce您可能感兴趣
- mapreduce分布式
- mapreduce编程
- mapreduce灰色
- mapreduce shell
- mapreduce role
- mapreduce notebook
- mapreduce控制台
- mapreduce任务
- mapreduce文件
- mapreduce源代码
- mapreduce hadoop
- mapreduce集群
- mapreduce spark
- mapreduce数据
- mapreduce作业
- mapreduce hdfs
- mapreduce运行
- mapreduce maxcompute
- mapreduce程序
- mapreduce配置
- mapreduce yarn
- mapreduce oss
- mapreduce框架
- mapreduce案例
- mapreduce优化
- mapreduce wordcount
- mapreduce大数据