[帮助文档] 如何使用SparkStructuredStreaming实时处理Kafka数据
本文介绍如何使用阿里云 Databricks 数据洞察创建的集群去访问外部数据源 E-MapReduce,并运行Spark Structured Streaming作业以消费Kafka数据。
194 Spark Streaming实现实时WordCount
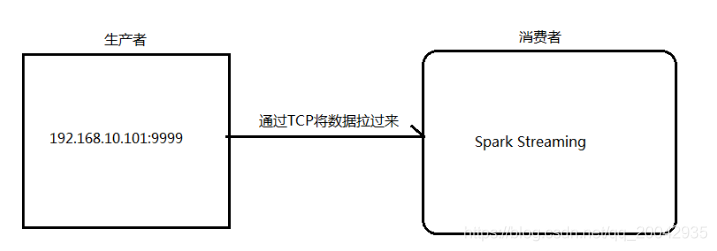
架构图:1.安装并启动生成者首先在一台Linux(ip:192.168.10.101)上用YUM安装nc工具yum install -y nc启动一个服务端并监听9999端口nc -lk 99992.编写Spark Streaming程序package cn.itcast.spark.streami...

[帮助文档] 如何创建EMRSparkStreaming节点并进行数据开发
EMR Spark Streaming节点用于处理高吞吐量的实时流数据,并具备容错机制,可以帮助您快速恢复出错的数据流。本文为您介绍如何创建EMR Spark Streaming节点并进行数据开发。
09【在线日志分析】之基于Spark Streaming Direct方式的WordCount最详细案例(java版)
1.前提 a. flume 收集--》flume 聚合--》kafka ,启动进程和启动kafka manager监控 08【在线日志分析】之Flume Agent(聚合节点) sink to kafka cluster b.window7 安装jdk1.7 或...
Spark Streaming和Flink的Word Count对比
准备: nccat for windows/linux 都可以 通过 TCP 套接字连接,从流数据中创建了一个 Spark DStream/ Flink DataSream, 然后进行处理, 时间窗口大小为10s 因为 示例需要, 所以 需要下载一个netcat, 来构造流的输入...
[帮助文档] 如何配置SparkStreaming类型作业
本文介绍如何配置Spark Streaming类型的作业。
[帮助文档] 如何通过DLAServerlessSpark提交SparkStreaming作业
本文介绍DLA Serverless Spark如何提交Spark Streaming作业以及Spark Streaming作业重试的最佳实践。
[帮助文档] 如何使用DLASparkStreaming访问LogHub
本文介绍了如何使用DLA Spark Streaming访问LogHub。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子





apache sparkstreaming相关内容
- apache spark streaming编程
- apache spark streaming区别
- flink apache spark streaming
- apache spark Streaming容错性
- apache spark streaming数据源
- apache spark streaming dstream操作
- apache spark streaming操作
- apache spark streaming简介
- apache spark streaming学习笔记
- apache spark summit east streaming
- apache spark streaming计算
- apache spark streaming checkpoint
- apache spark streaming binlog
- apache spark structured streaming
- 大数据apache spark streaming
- apache spark streaming实时计算
- apache spark streaming框架
- emr apache spark streaming
- apache spark streaming应用程序
- apache spark streaming优化
- apache spark全集末尾structured streaming续集
- apache spark streaming项目实战笔记
- apache spark streaming flume数据
- apache spark streaming实战
- apache spark streaming流处理
- apache spark streaming at bing scale
- apache spark Streaming Kafka
- apache spark streaming连接kafka
- 流式计算apache spark streaming
- apache spark streaming应用
- apache spark streaming快速入门
- apache spark streaming算子
- apache spark streaming架构原理
- apache spark streaming window
- apache spark streaming分析
- apache spark streaming容错机制
- apache spark streaming容错
- apache spark streaming机制
- apache spark streaming foreachrdd
- apache spark streaming transform
- apache spark Streaming原理
- apache spark streaming direct
- apache spark streaming服务
- apache spark Streaming SQL
- apache spark streaming数据统计
- apache spark Streaming如何保证
- apache spark streaming文件典型方法是什么意思
- apache spark streaming文件典型
apache spark更多streaming相关
- apache spark streaming方法
- apache spark streaming小文件
- apache spark streaming作用是什么
- apache spark入门streaming
- apache spark summit eu streaming
- apache spark streaming loghub
- apache spark streaming作业运行
- apache spark streaming sql pv uv统计
- flink相比传统apache spark streaming区别
- apache spark streaming运行
- apache spark streaming receiver
- apache spark streaming文件
- apache spark streaming kafka stream
- apache spark streaming流计算
- kafka apache spark streaming
- apache spark streaming文件典型是什么意思
- apache spark Streaming例子整理
- apache spark streaming函数
- apache spark streaming kafka数据
- building apache spark streaming
- apache spark structed streaming
- apache spark Streaming预测股票走势
- apache spark streaming vs
- apache spark streaming步骤
- 配置apache spark streaming
- apache spark streaming采集
- apache spark streaming storm
- noxmobi系统使用流式计算apache spark streaming
- apache spark streaming mllib
- apache spark streaming流程
- apache spark streaming系统
- apache spark Streaming框架应用
- apache spark streaming数据清理
- apache spark streaming func
- apache spark使用Streaming SQL统计
- apache spark streaming resource
- apache spark Streaming DStreams
- apache spark streaming文档
- data apache spark streaming
- apache spark streaming loghub报错
- apache spark入门streaming dstream
- apache spark streaming函数分析
- 日志分析apache spark streaming
- apache spark Streaming概念
apache spark您可能感兴趣
- apache spark serverless
- apache spark阿里云
- apache spark emr
- apache spark报错
- apache spark Connector
- apache spark版本
- apache spark架构
- apache spark yarn
- apache spark实验
- apache spark编程
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark Hadoop
- apache spark大数据
- apache spark rdd
- apache spark MaxCompute
- apache spark运行
- apache spark summit
- apache spark集群
- apache spark模式
- apache spark分析
- apache spark学习
- apache spark机器学习
- apache spark实战
- apache spark flink
- apache spark Scala
- apache spark任务
- apache spark程序