随着大数据发展,中小企业是否有必要自建从开源Hadoop数据湖架构到云上托管数据入湖等完整的大数据体
随着大数据发展,中小企业是否有必要自建从开源Hadoop数据湖架构到云上托管数据入湖等完整的大数据体系?
[帮助文档] 启用Trino语法进行数据湖分析
StarRocks 3.x版本在进行数据湖分析时,支持兼容Trino语法。本文介绍如何在StarRocks中利用Trino语法进行数据湖分析,特别是针对从Trino迁移至StarRocks的用户,旨在实现无缝切换且无需更改原有SQL语句。

[帮助文档] 快速使用数据湖分析实例
数据湖分析版实例适用于查询存储在Apache Hive、Apache Iceberg、Apache Hudi以及Apache Paimon等多种数据湖上的数据,并涵盖OSS、OSS-HDFS、HDFS等平台,无需数据迁移即可实现快速的数据湖查询分析,且其性能比Presto高出3到5倍。本文以创建Hi...
Hudi数据湖技术引领大数据新风口(四)核心概念
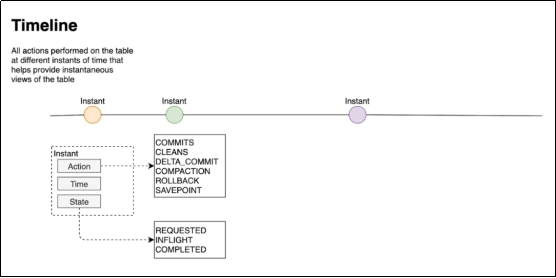
第3章 核心概念3.1 基本概念3.1.1 时间轴(TimeLine)Hudi的核心是维护表上在不同的即时时间(instants)\执行的所有操作的时间轴(timeline)\,这有助于提供表的即时视图,同时还有效地支持按到达顺序检索数据。一个instant由以下三个部分组成:*1)Instant ...
Hudi数据湖技术引领大数据新风口(三)解决spark模块依赖冲突
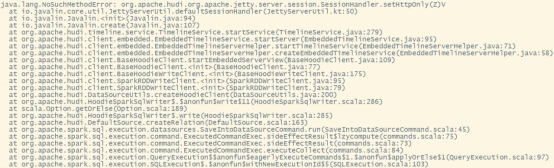
解决spark模块依赖冲突修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。1)修改hudi-spark-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty:vim /opt/software/hudi-0.12....
Hudi数据湖技术引领大数据新风口(二)编译安装
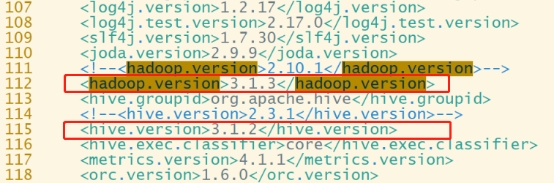
第2章 编译安装2.1 编译环境准备本教程的相关组件版本如下:Hadoop3.1.3Hive3.1.2Flink1.13.6,scala-2.12Spark3.2.2,scala-2.12(1)安装Maven(1)上传apache-maven-3.6.1-bin.tar.gz到/opt/softwa...
Hudi:数据湖技术引领大数据新风口
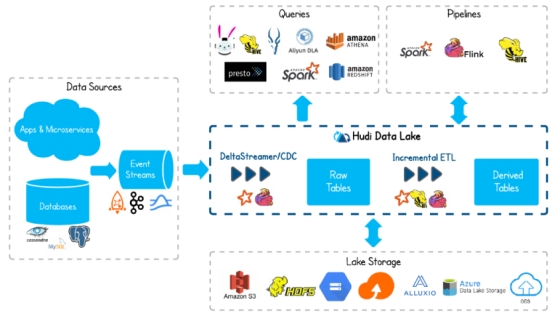
Hudi:数据湖技术引领大数据新风口1.1 Hudi简介Apache Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接引入数据湖。Hudi提供了表、事务、高效的upserts/delete、高...

大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
一、概述Hudi(Hadoop Upserts Deletes and Incrementals),简称Hudi,是一个流式数据湖平台,支持对海量数据快速更新,内置表格式,支持事务的存储层、 一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具,它可以以极低的延迟将数据快...
[帮助文档] 介绍如何通过数据集成实时入湖
本文以MySQL实时入湖写入至OSS场景为例,为您介绍如何通过数据集成实时入湖。
[帮助文档] 如何使用StarRocks的数据湖分析能力查询阿里云OSS
本文为您介绍如何使用StarRocks的数据湖分析能力查询阿里云OSS。
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。