
Python爬虫:scrapy框架请求参数meta、headers、cookies一探究竟(2)
cookies上面的信息中少了个response.cookies,如果添加上回报错:AttributeError: 'TextResponse' object has no attribute 'cookies'说明响应是不带cookies参数的通过 http://httpbin.org/cooki...
Python爬虫:scrapy框架请求参数meta、headers、cookies一探究竟(1)
对于scrapy请参数,会经常用到,不过没有深究今天我就来探索下scrapy请求时所携带的3个重要参数headers, cookies, meta原生参数首先新建myscrapy项目,新建my_spider爬虫通过访问:http://httpbin.org/get 来测试请求参数将爬虫运行起来# -...

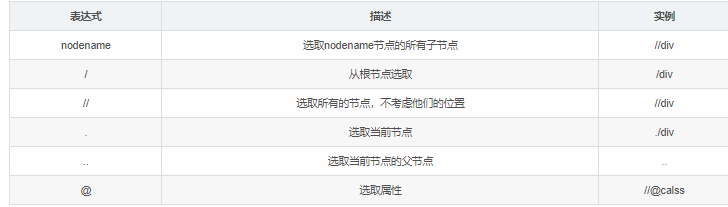
python爬虫:scrapy框架xpath和css选择器语法
Xpath基本语法一、常用的路径表达式:举例元素标签为artical标签二、谓语谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点三、通配符Xpath通过通配符来选取未知的XML元素四、取多个路径使用“|”运算符可以选取多个路径五、Xpath轴轴可以定义相对于当前节点的节点集六、功能...
python爬虫:scrapy框架Scrapy类与子类CrawlSpider
Scrapy类name 字符串,爬虫名称,必须唯一,代码会通过它来定位spiderallowed_domains 列表,允许域名没定义 或 空: 不过滤,url不在其中: url不会被处理,域名过滤功能: settings中OffsiteMiddlewarestart_urls:列表或者元组,任务的...
【Python爬虫8】Scrapy 爬虫框架
安装Scrapy 新建项目 1定义模型 2创建爬虫 3优化设置 4测试爬虫 5使用shell命令提取数据 6提取数据保存到文件中 7中断和恢复爬虫 使用Portia编写可视化爬虫 1安装 2标注 3优化爬虫 4检查结果 使用Scrapely实现自动化提取 1.安装Scrapy 用pip命令安装Scr...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。








Python爬虫scrapy相关内容
Python更多爬虫相关
- Python爬虫pandas
- Python web爬虫
- Python爬虫beautifulsoup
- Python爬虫图片爬取
- Python爬虫王者荣耀
- Python爬虫数据处理
- Python爬虫数据存储
- Python爬虫并发
- Python爬虫动态加载
- Python爬虫爬取
- Python爬虫数据
- Python爬虫库
- Python爬虫实战
- Python爬虫抓取
- Python爬虫技术
- Python爬虫入门
- Python爬虫网页
- Python爬虫解析
- Python爬虫入门教程
- Python爬虫urllib
- Python爬虫数据抓取
- Python爬虫框架项目实战
- Python爬虫工具
- Python爬虫入门教程爬取
- Python爬虫电影
- Python爬虫xpath
- Python爬虫请求
- Python爬虫百度
- Python爬虫app
- Python爬虫采集
- Python爬虫分析
- Python爬虫原理
- Python爬虫实例
- Python爬虫入门教程数据抓取
- Python爬虫文章
- Python爬虫代理
- Python爬虫请求头
- Python爬虫requests库
- Python爬虫线程
- Python爬虫验证码
- Python爬虫商品
- Python技术爬虫
- Python爬虫技术框架
- Python爬虫数据分析
- Python网络爬虫爬虫
- Python技术框架项目实战爬虫
- Python爬虫下载
- Python爬虫登录
- Python爬虫get
- Python爬虫csdn