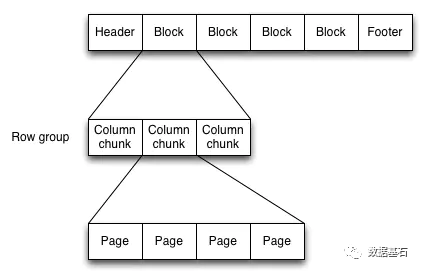
【Parquet】Spark读取Parquet问题详解……
「困惑」spark sql 读取 parquet 文件,stage 生成任务 4 个 task,只有一个 task 处理数据,其它无spark 任务执行 apache iceberg rewriteDataFiles 合并小文件(parquet 文件),发现偶然无变化「Parquet 文件详解」一个...
Spark使用JindoFS计算加速读取parquet数据的前提是什么?
Spark使用JindoFS计算加速读取parquet数据的前提是什么?

spark读取parquet 找不到 org/apache/hadoop/fs/FSDataInputStream
在spark-env里加上了export SPARK_DIST_CLASSPATH=$(hadoop classpath)也没用 有人遇到过吗
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。
社区圈子






apache spark您可能感兴趣
- apache spark入门
- apache spark大数据
- apache spark配置
- apache spark安装
- apache spark单机
- apache spark环境搭建
- apache spark案例
- apache spark测试
- apache spark streaming
- apache spark分布式
- apache spark SQL
- apache spark Apache
- apache spark数据
- apache spark rdd
- apache spark Hadoop
- apache spark MaxCompute
- apache spark运行
- apache spark集群
- apache spark summit
- apache spark模式
- apache spark学习
- apache spark分析
- apache spark机器学习
- apache spark实战
- apache spark Scala
- apache spark flink
- apache spark程序
- apache spark操作