使用python读取word统计词频并生成词云
1、准备需要用到python-docx,jieba和wordcloud模块,先installpip3 install jieba pip install wordcloud2、开始代码(1)导入需要用到的模块import re import jieba import docx from wordcl...
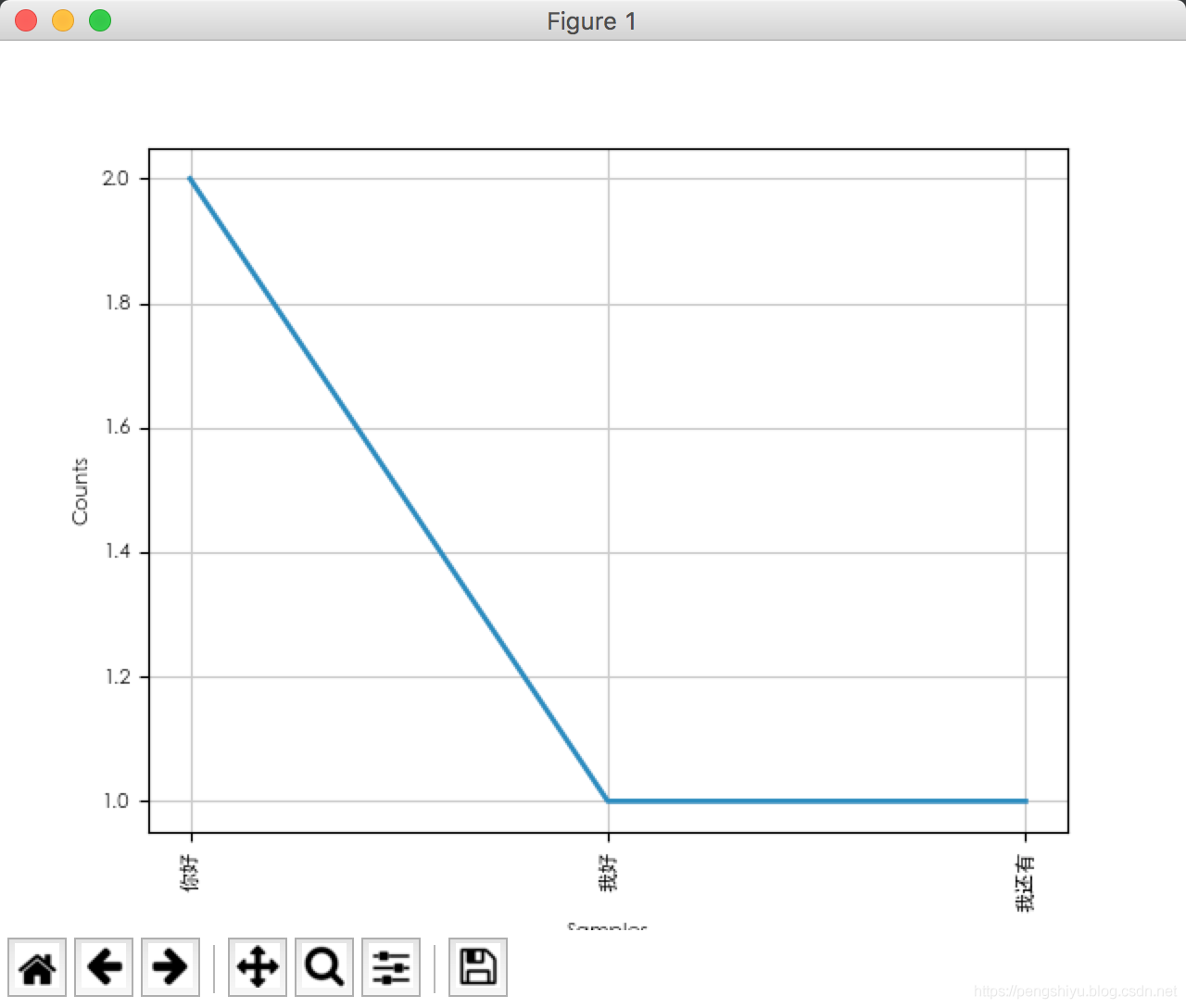
Python:使用nltk统计词频并绘制统计图
测试环境:macpython3.6.5安装pip install nltk代码示例# -*- coding: utf-8 -*-from nltk import FreqDistfrom matplotlib import rcParams# matplotlib 设置中文字体rcParams["f...

Python编程:使用defaultdict统计词频
# -*- coding: utf-8 -*- # 要统计的词 words = ["腾讯", "百度", "阿里巴巴", "百度", "阿里巴巴"] # 方式一:使用dict方式 counter1 = {} for word in words: counter1[word]...
Python 使用collections统计词频
方法1dictionary = {} for word in word_list: if not word in dictionary: dictionary[word] = 1 else: dictionary[word]+= 1 print(dictionary)输出 {'I': 2, '...
Python:使用nltk统计词频并绘制统计图
测试环境:macpython3.6.5安装pip install nltk代码示例# -*- coding: utf-8 -*- from nltk import FreqDist from matplotlib import rcParams # matplotlib 设置中文字体 rcParam...
python实战,中文自然语言处理,应用jieba库来统计文本词频
模块介绍 安装:pip install jieba 即可 jieba库,主要用于中文文本内容的分词,它有3种分词方法: 1. 精确模式, 试图将句子最精确地切开,适合文本分析: 2. 全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义; 3. 搜索引擎模式,在精确模式的基础...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。