使用Python爬虫获取Firefox浏览器的用户评价和反馈
在当今数字化的世界中,浏览器是我们日常生活中必备的工具之一。Firefox浏览器作为首批备受欢迎的开源浏览器,拥有庞大的用户群体。了解Firefox的用户浏览器的评价和反馈,对于改进和优化浏览器功能具有重要意义。所以今天我们重点分享下如何利用Python爬虫来获取Firefox浏览器的用户评价和反馈...
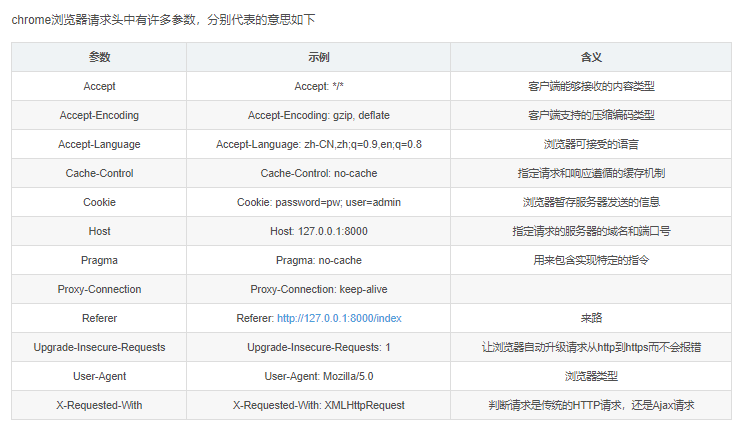
Python爬虫:浏览器请求头参数RequestHeaders
Python爬虫:浏览器请求头参数RequestHeaders

Python爬虫:常用的浏览器请求头User-Agent
user_agent = [ "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50", "Mozilla/5...
Python爬虫使用浏览器的cookies:browsercookie
技术文章来源于猿人学Python教程,如需转载,请加猿人学Python公众号联系。 很多用Python的人可能都写过网络爬虫,自动化获取网络数据确实是一件令人愉悦的事情,而Python很好的帮助我们达到这种愉悦。然而,爬虫经常要碰到各种登录、验证的阻挠,让人灰心丧气(网站:天天碰到各种各样的爬虫抓我...
【资料下载】Python 第六讲——Python爬虫进阶 JS分析—浏览器指纹
直播时间:直播时间:03月07日(周四) 20:00——21:00 主讲人 :冷月 —— 阿里特邀技术专家 网络安全工程师, 擅长JS加解密, 风控黑盒分析。用破解的思路, 构建更强的防御。 直播介绍:随着爬虫与反爬竞争愈来愈烈, 验证码和用户登录系统难以继续阻挡爬虫的入侵. 于是浏览器指纹出现了,...
4.python爬虫浏览器伪装技术
#python爬虫的浏览器伪装技术 #爬取csdn博客,会返回403错误,因为对方服务器会对爬虫进行屏蔽,此时需要伪装成浏览器才能爬取 #浏览器伪装,一般通过报头进行。 import urllib.request url="http://blog.csdn.net/bingoxubin/articl...
Python 爬虫基础 - 浏览器伪装
前面学习了Urllib模块里面最最基本的GET和POST操作。现在做个简单的例子,比如我打算爬http://www.oschina.net/ 的页面 如果使用一样的方法 import urllib.request url = "http://www.oschina.net/" data = urll...
分享个自己Python爬虫时的浏览器标识库
本人使用的Python3版本,python2未做测试 如有问题很可能出在 toObj函数上toObj函数具体参考:https://stackoverflow.com/questions/1305532/convert-Python-dict-to-object UserAgent.py class ...
本页面内关键词为智能算法引擎基于机器学习所生成,如有任何问题,可在页面下方点击"联系我们"与我们沟通。







